LLM 的局限性
大语言模型(LLM)虽然在自然语言处理方面表现出色,但在某些特定任务上,其能力甚至不如一些基础的计算机程序。尤其是在需要精确 计算 或进行实时 搜索 的场景下,LLM 往往显得力不从心。
以下是一个使用文心大模型进行简单乘法计算的例子:
模型的输出结果为:
['4.1乘以7.9等于31.79。']然而,正确的计算结果是 $4.1 * 7.9 = 32.39$。很明显,文心大模型给出了错误的答案。

对于这类简单的数学运算,传统的计算机程序(例如 Python 的 numexpr 库)可以轻松、准确地完成,更复杂的计算也不在话下。但这却暴露了 LLM 在精确计算方面的短板。
我们在 @sec-RAG 部分讨论过,使用 RAG 技术可以缓解 LLM 知识更新不及时、产生幻觉以及处理私有数据等问题。但是,对于像 @lst-ernie_calc 中展示的计算错误问题,RAG 并不能有效解决。
为了让 LLM 更好地服务于我们,我们需要找到克服这些局限性的方法。Agent 技术应运而生,提供了一种有效的解决方案。
借助 Agent,我们不仅能解决上述的 计算 难题,还能解锁 LLM 的更多潜能,让它能够执行更广泛的任务,甚至实现一些我们之前难以想象的应用。
什么是 Agent?
在日常生活中,我们解决问题时常常会借助外部工具,比如用计算器进行数学运算,或者通过搜索引擎获取信息。“君子性非异也,善假于物也”,Agent 的核心思想与此类似,它让 LLM 也能够像人类一样利用外部工具。
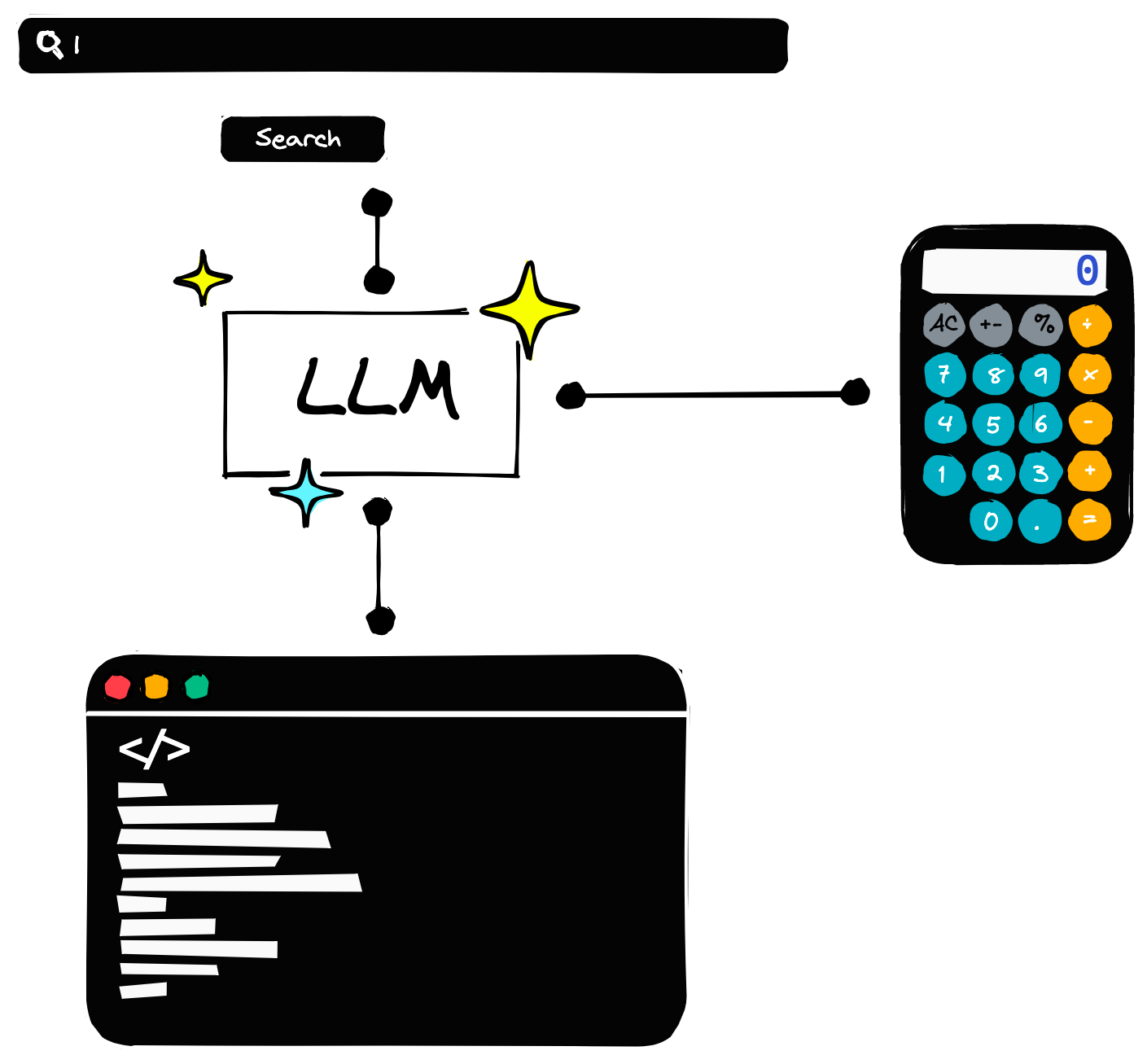
从本质上讲,Agent 可以理解为一种被赋予了使用外部工具能力的特殊 LLM。它不再仅仅依赖模型内部的知识,而是可以通过调用工具来获取信息或执行操作。
Agent 的工作流程,与我们人类使用工具解决问题的过程非常相似:
- 思考 (Thought): 首先,Agent 会分析当前的任务和目标。
- 工具选择 (Tool Selection): 然后,它会判断有哪些可用的工具能够帮助完成任务,并选择最合适的工具。
- 行动 (Action): 接着,Agent 会调用选定的工具,执行具体的操作(例如,调用计算器、访问 API、执行代码等)。
- 观察 (Observation): 执行行动后,Agent 会观察工具返回的结果或环境的变化。
- 迭代 (Iteration): Agent 会根据观察到的结果,进行新一轮的思考,决定下一步行动,重复步骤 1-4,直到任务完成。
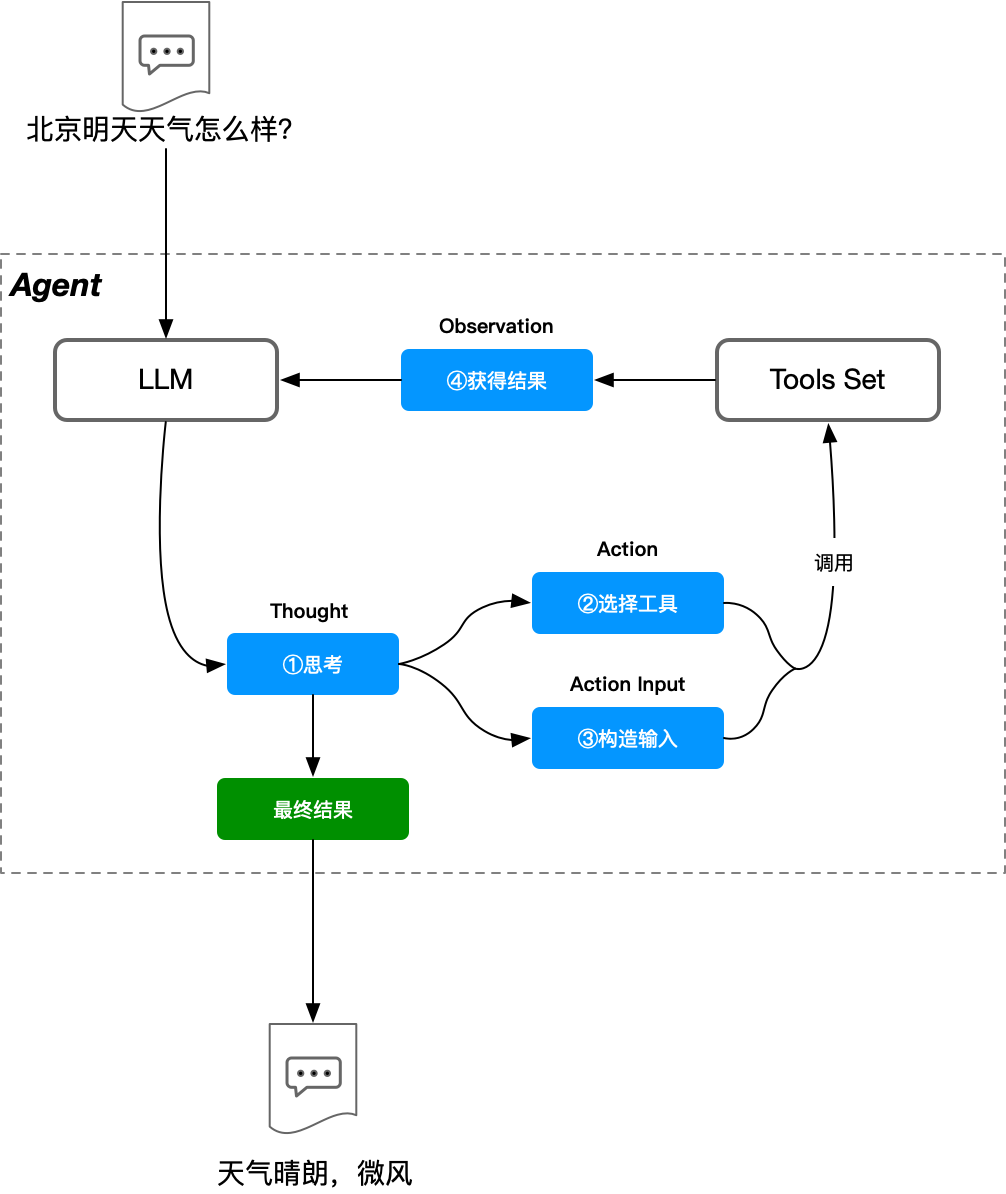
如 @fig-agent_seq 所示,Agent 虽然本质上是 LLM,但其核心区别在于拥有 思考 (Thought) 的能力和可调用的 工具集 (Tools Set)。这种分步思考、利用工具的方式,使得 Agent 能够处理更复杂的任务,并通过多次推理或与工具交互来获得更准确、更可靠的结果。
例如,根据 B 站 UP 主分享的视频,像 AutoGPT 这样的高级 Agent,甚至能够自主完成查询文献、学习文献,并最终根据指定的论文题目完成写作的整个复杂流程,这展示了 Agent 技术的巨大潜力。
ReAct 模式
需要明确的是,这里的 ReAct 并非软件工程中的 reactor 设计模式[^1],也不是 Meta 公司开发的前端框架 react[^2]。它特指由 Yao 等研究者在 [-@yao2022react_online] 和 [-@yao2022react] 中提出的一种将 推理 (Reasoning) 和 行动 (Action) 相结合的通用范式,旨在提升 LLM 在语言推理和决策任务上的表现。
ReAct 模式的核心思想是让 LLM 以一种交错的方式生成 推理轨迹 (reasoning traces) 和 文本动作 (text actions)。LLM 首先进行推理思考(例如,“我需要计算 4.1 * 7.9”),然后执行相应的动作(例如,调用计算器工具),接着观察动作结果,再进行下一步推理。这种方式使得模型能够从上下文和之前的动作结果中提取信息,指导后续的推理和行动。正如 [-@yao2022react_online] 所述,ReAct 有效地结合了推理和行动阶段,显著提升了 LLM 的性能。
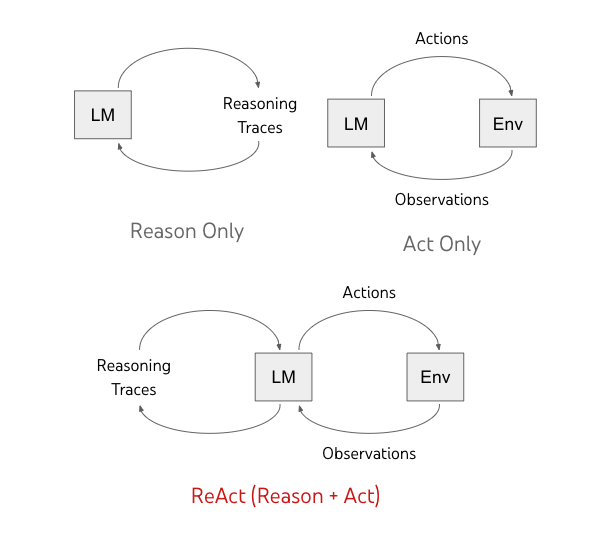
实际上,这个流程与 @fig-agent_seq 展示的基本 Agent 流程是一致的。
INFO
ReAct 模式通常也被称为 Action Agent。在这种模式下,Agent 的下一步行动直接由上一步的输出(包括观察结果和之前的思考)决定。它本质上可以看作是一种精心设计的 Prompt 策略,更适用于规模相对较小、步骤不太复杂的任务。
PlanAndExecute 模式
如上所述,Action Agent(ReAct 模式)在处理小型任务时表现良好。但当任务规模增大、复杂度提高时,完全依赖 Agent 的即时推理和行动来驱动整个流程,可能会遇到挑战。Action Agent 可能会在长流程中“迷失方向”,或者难以稳定地选择正确的工具和执行顺序。
为了让 Agent 能够更可靠、更稳定地处理复杂任务,研究者们提出了 PlanAndExecute 模式。这种模式的核心在于将任务的 计划 (plan) 制定阶段与 执行 (execute) 阶段分离开来。
PlanAndExecute 模式的工作流程通常如下:
- 计划阶段 (Planning): 首先,使用一个 LLM(可以称为“规划器 Planner”)来分析用户请求,并制定一个解决该请求的、包含明确步骤的详细计划。
- 执行阶段 (Execution): 然后,针对计划中的每一个步骤,再调用一个 Agent(通常是 Action Agent 类型,可以称为“执行器 Executor”)来具体完成该步骤的任务。
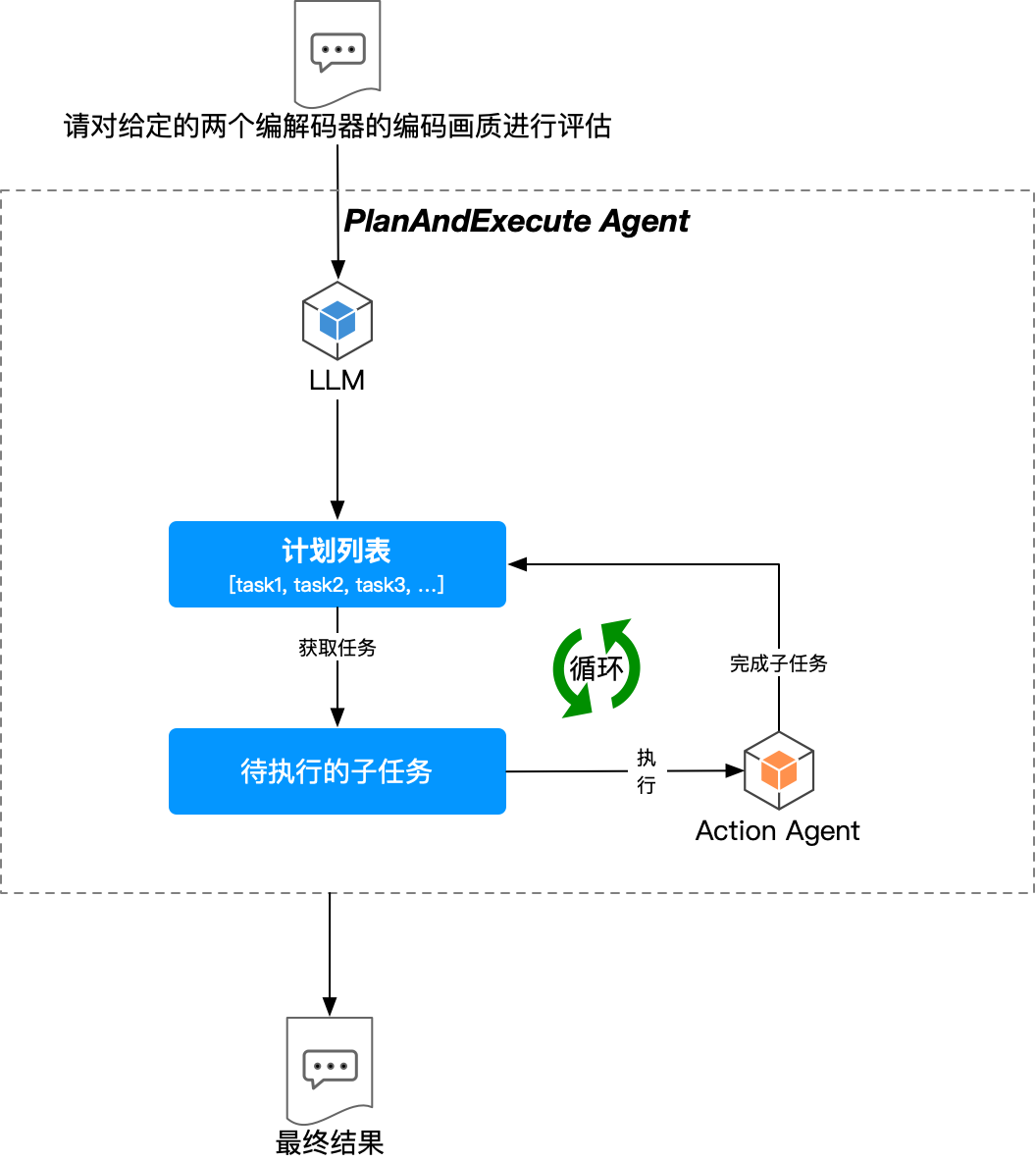
这种“先规划、后执行”的方式提高了 Agent 处理复杂任务的结构性和可靠性。目前,类似 BabyAGI[^3] 的项目也采用了相似的思路。更多关于 PlanAndExecute 模式的底层原理和实现细节,可以参考 [-@wang2023planandsolve]。
INFO
该模式通过将大型任务分解为一系列更小、更易于管理的目标和步骤,使得 Agent 能够更有效地应对复杂挑战。
这种方法的优势在于通过明确的 计划 让整个过程更加“按部就班”,从而提升了可靠性。但其代价是需要进行更多的 LLM 调用(至少一次用于规划,多次用于执行各步骤),因此通常会带来更高的延迟和运行成本。[^4]
Multi-Agent 系统
到目前为止,我们讨论的 Agent 场景都属于 Single-Agent,即由一个独立的 Agent 来完成用户提出的任务。然而,在现实世界中,许多复杂问题需要不同角色的专家协作才能解决。Multi-Agent 系统将这种协作思想引入了 Agent 领域。
根据 [-@multiagentintro],Multi-Agent 是分布式人工智能的一个分支,强调不同 Agent 之间的协作以完成共同目标,早期主要应用于强化学习和博弈论 (game theory) 等领域。近年来,随着 LLM 的发展,研究者开始探索利用 Multi-Agent 系统的能力来增强 LLM 的应用潜力。例如,[-@talebirad2023multiagent] 提出了一种框架,构建一个协作环境,让多个具有不同属性和角色的 Agent(可能由不同的 LLM 驱动)协同工作,从而更高效地处理复杂任务。
Multi-Agent 的定义
从本质上讲,Multi-LLM-Agent 系统 是指涉及多个(通常由 LLM 驱动的)Agent 协同工作的系统。与传统的 Single-Agent 系统不同,Multi-Agent 系统由多个 AI Agent 组成,每个 Agent 可能专注于不同的领域或扮演不同的角色(如规划者、执行者、批评家、代码审查员等),它们通过相互通信和协作,共同达成一个更宏大的目标,提供更全面、更细致的解决方案。
正如 @fig-autogen 展示的 AutoGen 架构图,Multi-Agent 系统可以通过不同 Agent 之间的对话和协作,完成非常复杂的任务,例如软件开发、科学研究等。
![微软 AutoGen 项目的 Multi-Agent 架构示例[^5]](/assets/autogen_2.CbxOtW_y.webp)
Multi-Agent 系统相比 Single-Agent 具有以下优势[^6]:
- 更强的专业技能组合: 系统中可以包含各自领域知识的专家 Agent,使得整体能够提供更深入、更准确的响应。不同专业知识的结合确保了解决方案的全面性和可靠性。
- 更优的问题解决能力: 复杂问题往往需要多角度、综合性的方法。Multi-Agent 系统通过整合各个 Agent 的“集体智慧”,利用不同 Agent 的优势互补,能够解决单个 LLM 或单个 Agent 难以应对的难题。正所谓“众人拾柴火焰高”。
- 更高的稳定性与鲁棒性: 由于任务由多个 Agent 协作完成,系统降低了单点故障的风险。如果一个 Agent 遇到问题或能力限制,其他 Agent 可以介入或补充,确保整体任务的稳定推进。
- 更好的适应性与可扩展性: 在动态变化的环境中,适应性至关重要。Multi-Agent 系统可以更容易地进行扩展,例如通过无缝集成新的 Agent 来应对新出现的挑战或增加新的功能。