Win整合包下载地址: https://pan.baidu.com/s/1ODhqN-GiaHoGdU-ml3kCUQ?pwd=i2ui GitHub地址: https://github.com/jianchang512/speech2text-df
在语音转写领域,大型语言模型通常针对英语进行优化,而对于东方语言(如中文方言、粤语、越南语、维吾尔语、菲律宾语等小语种)的识别效果往往不尽如人意。
为了解决这一问题,DataoceanAI 团队推出了开源项目 Dolphin,一个专门针对东方语言训练的语音转写模型。
为了让更多非技术用户也能轻松使用这一强大的模型,我开发了一个用户友好的 UI 界面和整合包。
以下是该工具的详细使用文档,旨在帮助用户快速上手,体验东方语言语音转写的便捷与高效。
功能概述
Dolphin 模型支持多种东方语言的语音转写,我的整合包在此基础上进一步简化了操作流程,通过一个直观的 UI 界面,用户只需上传音频文件并选择目标语言,即可获得转写结果,输出格式默认为 SRT(字幕文件格式),也支持其他格式(如 JSON或txt)。
界面与使用步骤
以下是基于界面截图的使用步骤说明:
访问工具
启动程序后,工具会自动打开一个网页界面,默认地址为http://127.0.0.1:5080。您也可以手动在浏览器中输入该地址访问。上传音频或视频文件
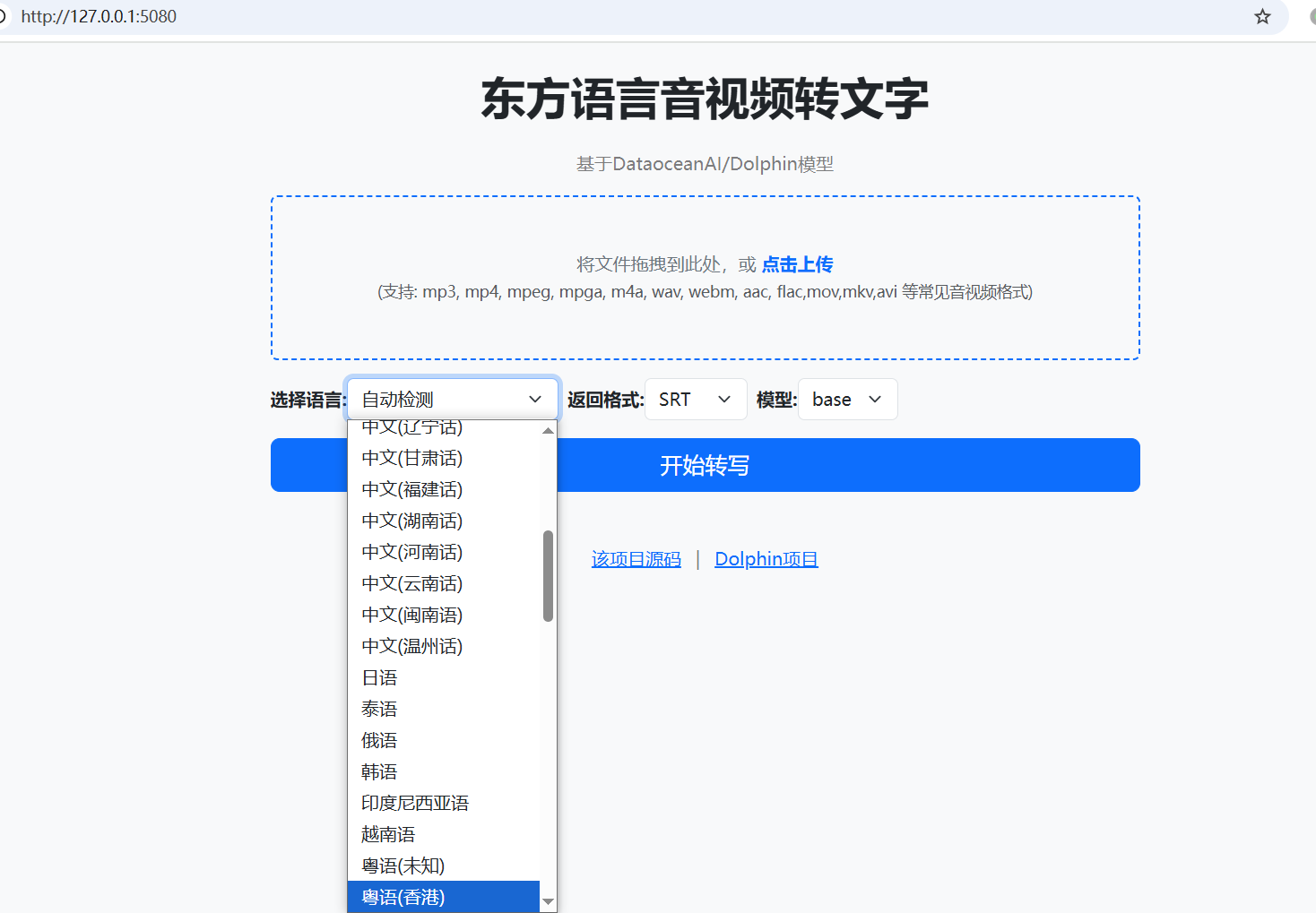
在界面中,点击“选择文件”按钮,从本地选择需要转写的音频文件。支持的格式包括 mp3、mp4、mpeg、mpga、m4a、wav、webm、aac、flac、mov、mkv、avi 等。选择语言
在“语言选择”下拉菜单中,选择目标语言,例如中文普通话、中文四川话、粤语等。如果不确定音频语言,可以选择“自动检测”,模型会尝试自动识别语言。选择返回格式
默认返回SRT字幕,也可以选择txt或json
开始转写
点击“开始转写”按钮,工具会将音频文件上传至服务器,并调用 Dolphin 模型进行转写。转写过程包括以下步骤:- 使用 FFmpeg 将音频转换为 WAV 格式。
- 将音频切分为小片段以提高处理效率。
- 对每个片段进行语音识别。
- 将识别结果组装为 SRT 格式(或用户指定的其他格式)。
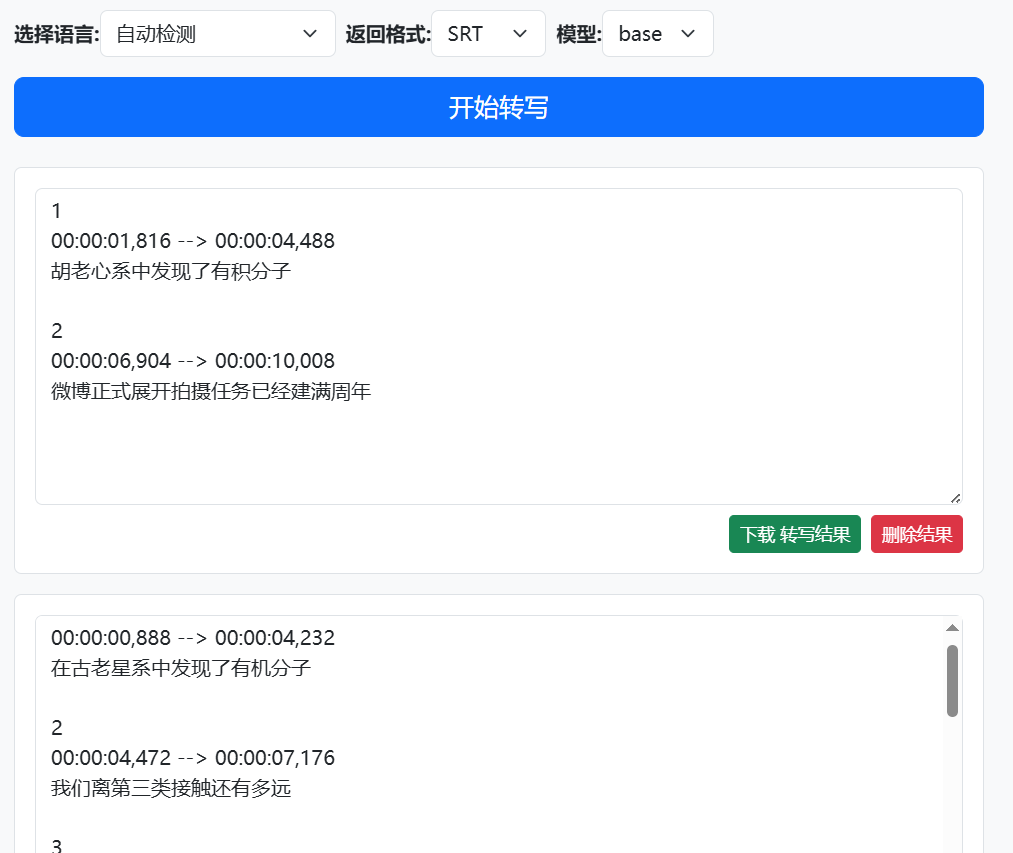
获取结果
转写完成后,结果会以 SRT 格式显示在界面中(或以 JSON 格式返回,取决于用户设置)。用户可以直接复制结果,或下载为文件用于字幕制作等场景。
API 接口使用说明(面向开发者)
对于有开发需求的用户,我提供的整合包还包含一个 API 接口,开发者可以通过 HTTP 请求调用转写功能。以下是 API 的使用方法:
- 端点:
/v1/audio/transcriptions - 方法:POST application/json
- 请求参数:
file:音频文件(必填,支持 mp3、mp4 等格式)。language:目标语言(可选,例如zh-CN/zh-SICHUAN等,若不填则自动检测)。response_format:返回格式(支持 "srt、json、txt")。
- 返回:
- 成功时:返回转写结果(SRT 格式的文本或 JSON 、txt格式)。
- 失败时:返回错误信息(如文件格式不支持、转写失败等)。
language支持的语言代码
| 语言代码 | 中文名字 |
|---|---|
| zh-CN | 中文(普通话) |
| zh-TW | 中文(台湾) |
| zh-WU | 中文(吴语) |
| zh-SICHUAN | 中文(四川话) |
| zh-SHANXI | 中文(山西话) |
| zh-ANHUI | 中文(安徽话) |
| zh-TIANJIN | 中文(天津话) |
| zh-NINGXIA | 中文(宁夏话) |
| zh-SHAANXI | 中文(陕西话) |
| zh-HEBEI | 中文(河北话) |
| zh-SHANDONG | 中文(山东话) |
| zh-GUANGDONG | 中文(广东话) |
| zh-SHANGHAI | 中文(上海话) |
| zh-HUBEI | 中文(湖北话) |
| zh-LIAONING | 中文(辽宁话) |
| zh-GANSU | 中文(甘肃话) |
| zh-FUJIAN | 中文(福建话) |
| zh-HUNAN | 中文(湖南话) |
| zh-HENAN | 中文(河南话) |
| zh-YUNNAN | 中文(云南话) |
| zh-MINNAN | 中文(闽南语) |
| zh-WENZHOU | 中文(温州话) |
| ja-JP | 日语 |
| th-TH | 泰语 |
| ru-RU | 俄语 |
| ko-KR | 韩语 |
| id-ID | 印度尼西亚语 |
| vi-VN | 越南语 |
| ct-NULL | 粤语(未知) |
| ct-HK | 粤语(香港) |
| ct-GZ | 粤语(广东) |
| hi-IN | 印地语 |
| ur-IN | 乌尔都语(印度) |
| ur-PK | 乌尔都语 |
| ms-MY | 马来语 |
| uz-UZ | 乌兹别克语 |
| ar-MA | 阿拉伯语(摩洛哥) |
| ar-GLA | 阿拉伯语 |
| ar-SA | 阿拉伯语(沙特) |
| ar-EG | 阿拉伯语(埃及) |
| ar-KW | 阿拉伯语(科威特) |
| ar-LY | 阿拉伯语(利比亚) |
| ar-JO | 阿拉伯语(约旦) |
| ar-AE | 阿拉伯语(阿联酋) |
| ar-LVT | 阿拉伯语(黎凡特) |
| fa-IR | 波斯语 |
| bn-BD | 孟加拉语 |
| ta-SG | 泰米尔语(新加坡) |
| ta-LK | 泰米尔语(斯里兰卡) |
| ta-IN | 泰米尔语(印度) |
| ta-MY | 泰米尔语(马来西亚) |
| te-IN | 泰卢固语 |
| ug-NULL | 维吾尔语 |
| ug-CN | 维吾尔语 |
| gu-IN | 古吉拉特语 |
| my-MM | 缅甸语 |
| tl-PH | 塔加洛语 |
| kk-KZ | 哈萨克语 |
| or-IN | 奥里亚语 |
| ne-NP | 尼泊尔语 |
| mn-MN | 蒙古语 |
| km-KH | 高棉语 |
| jv-ID | 爪哇语 |
| lo-LA | 老挝语 |
| si-LK | 僧伽罗语 |
| fil-PH | 菲律宾语 |
| ps-AF | 普什图语 |
| pa-IN | 旁遮普语 |
| kab-NULL | 卡拜尔语 |
| ba-NULL | 巴什基尔语 |
| ks-IN | 克什米尔语 |
| tg-TJ | 塔吉克语 |
| su-ID | 巽他语 |
| mr-IN | 马拉地语 |
| ky-KG | 吉尔吉斯语 |
| az-AZ | 阿塞拜疆语 |
示例请求(使用 curl):
curl -X POST http://127.0.0.1:5080/v1/audio/transcriptions \
-F "file=@/path/to/audio.mp3" \
-F "language=zh-CN" \
-F "response_format=srt"示例请求(使用openai sdk)
from openai import OpenAI
client=OpenAI(base_url='http://127.0.0.1:5080/v1', api_key='123')
filename="15.wav"
with open(filename,'rb') as file:
transcript = client.audio.transcriptions.create(
file=(filename, file.read()),
model='base',
language='zh-CN',
response_format="srt"
)
print(transcript)返回示例(SRT 格式):
1
00:00:00,000 --> 00:00:02,000
你好,这是一段测试音频。
2
00:00:02,001 --> 00:00:04,000
希望转写结果准确。五、GPU支持
为减小整合包体积,默认不支持GPU,如果你需要支持,首先确保已安装配置好了CUDA12.x 环境,然后在 整合包文件夹中,双击 安装GPU支持.bat即可自动安装
六、注意事项
文件大小与时长
为保证转写效率,建议单个音频文件不超过 1GB,时长控制在 1 小时以内。过长的音频可能会导致处理时间较长。音频质量
音频质量会直接影响转写效果。建议使用清晰、无过多背景噪音的音频文件。第一次转写必须保持网络连接
需要在线下载nltk库对应语言的一些字典数据,建议每种语言都成功执行一次后,再考虑离线
常见问题
pip install时出错,请安装visual studio community 2022版本,工作负荷中选择使用c++的桌面开发,右侧下拉底部,额外再选中MSVC v140 v141 v1423项,安装成功后再重试- 提示
File is not zip等错误,删掉models文件夹内的nltk后,挂系统代理重试 - 缺少
ffmpeg,win下将ffmpeg.exe放在api.py目录下。Macos系统brew install ffmpeg安装
本项目开源地址: https://github.com/jianchang512/speech2text-df Dolphin模型仓库地址: https://github.com/DataoceanAI/Dolphin