2022 年 11 月,OpenAI 推出的 ChatGPT 聊天机器人风靡全球。它不仅能与人流畅地交流,还能编写代码、创作诗歌、撰写论文。ChatGPT 的出现,标志着大语言模型 (LLM) 时代的真正到来,甚至让曾经备受瞩目的“元宇宙”都黯然失色。
包括谷歌、亚马逊、百度、阿里巴巴等在内的各大科技巨头,纷纷投入巨额资金研发自己的大语言模型。
- 2023 年 2 月 8 日,谷歌发布了 Bard 聊天机器人,但在发布会上演示时出现错误,导致谷歌股价大幅下跌。
- 2023 年 2 月 24 日,Meta (Facebook 的母公司) 开源了 LLaMA 模型,供研究使用。
- 2023 年 3 月 14 日,斯坦福大学在 LLaMA 的基础上微调出了 Alpaca 模型,其性能直逼 GPT-3.5。
- 同一天,OpenAI 发布了功能更为强大的 GPT-4。
- 2023 年 3 月 16 日,百度发布了“文心一言”。
- 2023 年 4 月 11 日,阿里巴巴推出了“通义千问”。
- 2023 年 7 月 18 日,Meta 发布了 LLaMA 2。
- 2023 年 10 月 17 日,百度发布了“文心 4.0”。
- ……
学术界也掀起了对大模型的研究热潮,相关论文的数量呈现出爆炸式增长。
大语言模型家族概览
要理解大语言模型,就必须了解 Transformer 模型。Transformer 模型由 Google 于 2017 年提出,可以被看作是一个强大的“翻译器”,它由多个“编码器”(Encoder) 和“解码器”(Decoder) 组成,为大语言模型的发展奠定了坚实的基础。
之后,大模型的发展形成了两大主要方向:
- Encoder 流派 (自编码模型): 类似于“完形填空”高手,通过遮盖句子中的一些词语,然后预测这些被遮盖的词语是什么。BERT 是这一流派的代表。
- Decoder 流派 (自回归模型): 类似于“故事接龙”高手,根据已有的内容,预测接下来应该说什么。GPT 系列是这一流派的代表。
起初,像 BERT 这样的“完形填空”模型发展迅速。然而,OpenAI 的研究人员发现,只要不断扩大模型的规模 (参数量、数据量、计算量),像 GPT 这样的“故事接龙”模型的性能就会越来越好,这就是所谓的 Scaling Laws (规模法则)。因此,GPT 系列逐渐成为大模型发展的主流。
GPT 的演进之路
OpenAI 在大模型领域的研究堪称稳扎稳打,通过不断的探索和实践,逐步展现了大模型的各种能力:
- GPT-1 (2018): 提出了“预训练 + 微调”的方法。类似于先让模型阅读大量的书籍 (预训练),然后针对特定的任务进行专门的辅导 (微调)。
- GPT-2 (2019): 拥有更大的模型和更多的数据,能力也更强。它不仅能完成特定的任务,还能举一反三,处理一些之前没有见过的任务 (零样本/少样本学习)。
- GPT-3 (2020): 拥有 1750 亿参数,是个名副其实的巨无霸!它不仅能力更强,还学会了“上下文学习” (In-Context Learning,简称 ICL)。只要提供一些例子,它就能理解用户的意图并完成任务。这使得“提示词工程” (Prompt Engineering) 成为可能。GPT-3 还展现出了“涌现能力” (Emergent Ability),即在模型规模变大后,突然出现了一些意想不到的能力。
- Codex (2021): 基于 GPT-3,专门学习了大量的代码,成为了编程高手。GitHub Copilot 就是基于 Codex 开发的。
- InstructGPT (2022,GPT-3.5): 更加听话,更能理解人类的指令。这是通过“基于人类反馈的强化学习” (RLHF) 技术实现的。ChatGPT 最初就是基于 GPT-3.5。
从 2018 年到 2022 年,OpenAI 花费了五年多的时间,逐步探索出了大模型的各种能力。
如何高效使用大语言模型?
面对如此强大的大模型,我们应该如何使用呢?是从头开始训练一个,还是微调现有的模型,还是直接使用提示词工程?
简单来说:
- 传统自然语言理解任务 (如文本分类、情感分析): 如果有标注好的数据,微调现有模型通常效果更好。
- 自然语言生成任务 (如机器翻译、写作、画图): 这是大模型的强项!使用提示词工程通常就能解决问题。
- 知识密集型任务 (需要大量的背景知识): 可以使用“检索增强生成” (RAG) 技术,让大模型从外部知识库中获取信息。
- 推理任务: 大模型在规模变大后,推理能力会显著提升。但是对于数学计算等任务,最好还是让大模型调用外部工具 (Agent),避免出现“幻觉” (一本正经地胡说八道)。
大语言模型的局限性
尽管大模型非常强大,但它们并非完美无缺。除了性能、效率、成本等问题之外,还存在以下挑战:
- 安全问题: 大模型可能会生成有害、带有偏见的内容,需要严格控制。
- 幻觉问题: 大模型有时会一本正经地胡说八道,需要特别注意。
- 实践验证: 需要更多真实场景的测试,以确保模型能够应对现实世界的复杂问题。
- 模型对齐: 需要确保模型的行为符合人类的价值观。
- 模型可解释性: 我们对大模型内部运作机制的了解还很有限。
核心概念详解
Transformer 架构:这是由 Google 在 2017 年提出的一种新型神经网络架构,主要用于处理自然语言。它摒弃了传统的 RNN 和 CNN,引入了注意力机制,构建了 Encoder-Decoder 架构。Transformer 结构清晰,计算效率高,支持并行计算,使其在 NLP 任务中表现卓越。
编码器模型:Encoder 负责理解输入的句子,并生成一个向量,用于表示输入句子的特征信息。例如,输入 "I love NLP",输出可能是
[0.1, 0.2, 0.3, 0.4]。解码器模型:Decoder 则基于 Encoder 的输出以及自身的上下文信息生成输出句子。例如,输入
[0.1, 0.2, 0.3, 0.4],输出可能是 "I love machine learning"。编码器和解码器通过注意力机制进行交互。注意力机制:以下示例演示了编码器和解码器如何通过注意力机制进行交互。在这个过程中,编码器输出一个编码向量,代表输入句子的信息。解码器每生成一个词,都会查询一次编码器的输出,并生成一个注意力分布,指出当前最重要的编码器输出内容。解码器结合注意力信息和自身的上下文,生成新的预测词。解码器每预测一个词,就将其加入到上下文中,用于生成下一个词。这个动态的查询-生成过程,就是编码器和解码器通过注意力机制进行交互。
输入句子:I love NLP。 编码器: 输入:I love NLP。 输出:向量 [0.1, 0.2, 0.3, 0.4] 表示输入句子的特征信息。 解码器: 输入:[0.1, 0.2, 0.3, 0.4] 输出:I (此时解码器只生成了第一个词 I,并将其作为上下文信息。) 注意力:解码器的注意力机制会查询编码器的输出 [0.1, 0.2, 0.3, 0.4],并生成注意力分布 [0.6, 0.2, 0.1, 0.1],表示解码器当前更关注编码器第一个输出元素。 解码器: 输入:[0.1, 0.2, 0.3, 0.4],[0.6, 0.2, 0.1, 0.1] 上下文:I 输出:love (解码器利用注意力分布所强调的编码器输出信息,以及自身的上下文 I,生成 love 作为当前最佳输出。) ..... 解码器最终生成:I love machine learning。自回归模型:Transformer 的 Decoder 需要逐步生成词元,并将当前生成的词元信息加入到上下文中,用于生成下一个词元。例如,模型输入 "I love",输出 "I love NLP",然后基于 "I love NLP" 生成 "I love natural language processing"。每一步都基于前面生成的内容生成新的输出,这种生成策略被称为自回归 (Auto-regressive)。典型的 autoregressive 模型有 GPT-2、GPT-3 等。
掩码模型:掩码语言模型 (MLM) 需要对输入文本中的一些词元进行掩码,然后训练模型基于上下文来预测被掩码的词元。例如,输入句子 "I love [MASK] learning",输出 "I love machine learning"。模型需要填充 [MASK] 来预测掩码词,从而实现对上下文的理解。BERT 就是一种典型的掩码语言模型。
发展趋势
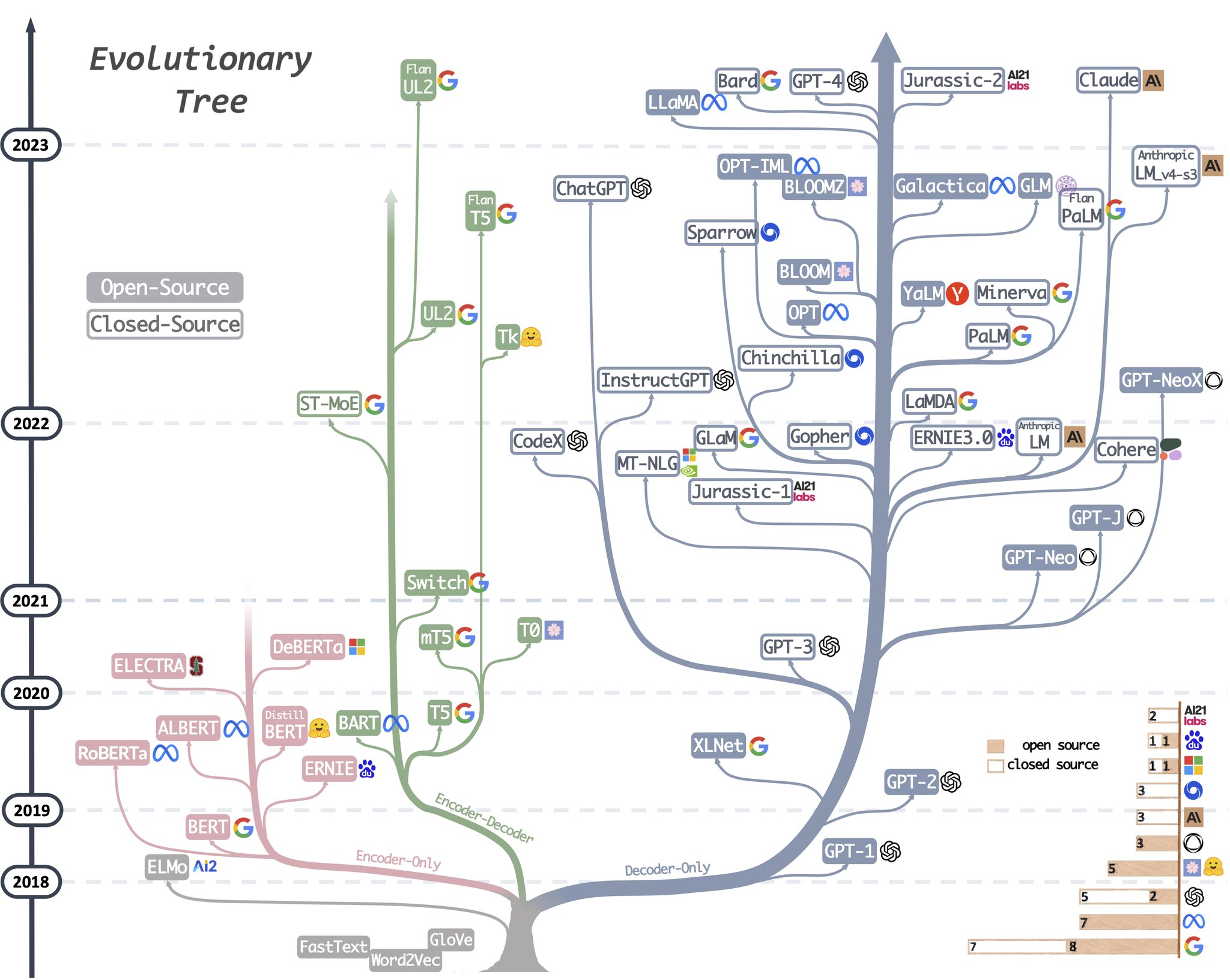
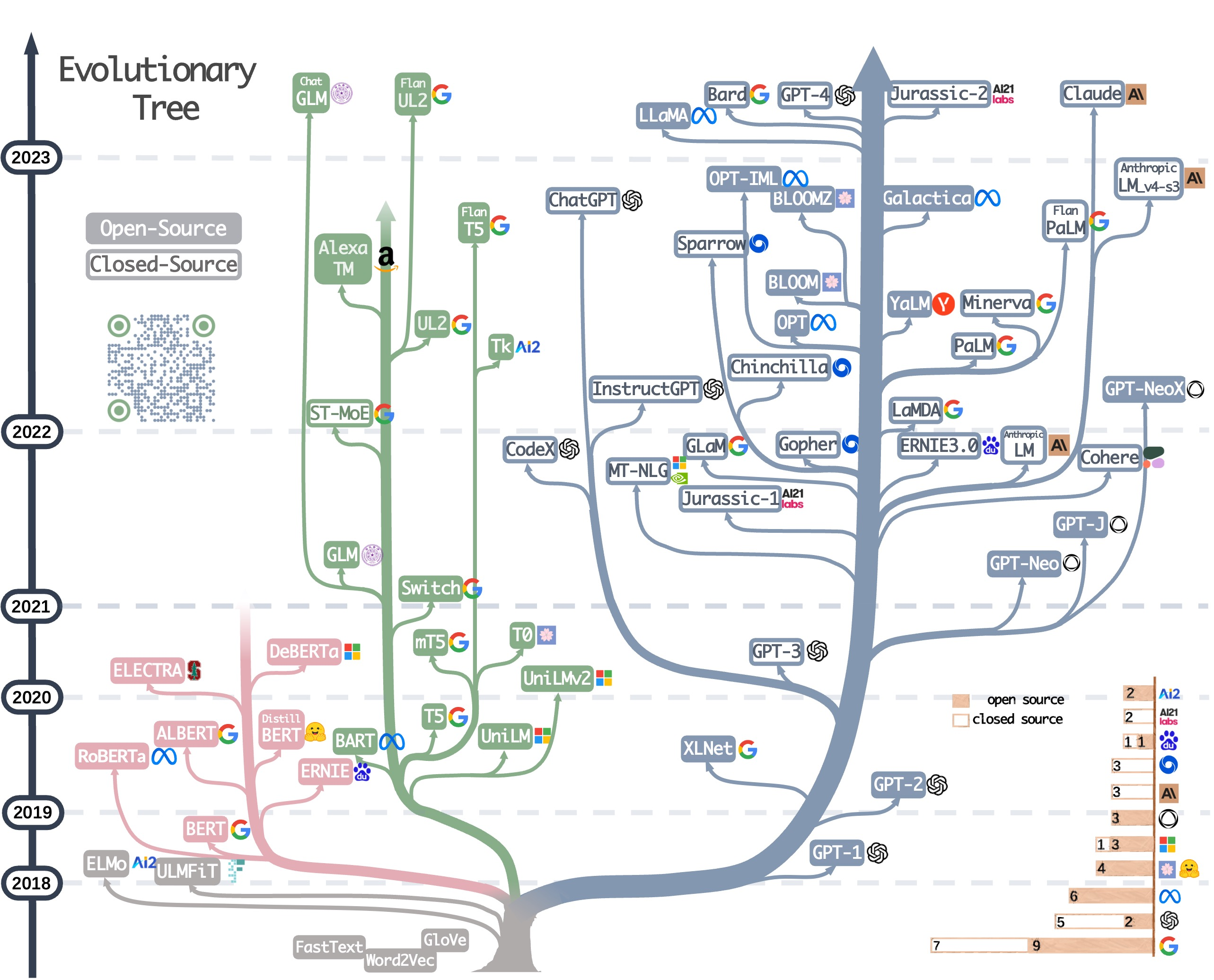
大语言模型进化树展示了 LLM 的发展历程,重点关注了相对知名的模型。同一分支上的模型关系更密切。不基于 Transformer 的模型用灰色表示,decoder-only 模型是蓝色分支,encoder-only 模型是粉色分支,encoder-decoder 模型是绿色分支。模型在时间轴上的垂直位置表示其发布时间。实心方块表示开源模型,空心方块则表示闭源模型。右下角的堆积条形图显示了各公司和机构的模型数量。
不同架构模型的特点
Encoder-only 模型:掩码语言模型是一种常见的训练方法,它通过上下文来预测句子中被遮掩的词,使模型能够更深刻地理解词与其上下文之间的关系。这些模型使用 Transformer 架构等技术在大型文本语料上训练,并在许多 NLP 任务中取得了最佳表现,如情感分析和命名实体识别。著名的掩码语言模型有 BERT、RoBERTa 和 T5。由于其在多种任务上的成功表现,掩码语言模型已成为自然语言处理领域的一种重要工具,但这些方法需要基于具体下游任务的数据集进行微调。在 LLM 的早期发展阶段,BERT 为仅编码器模型带来了最初的爆发式增长。(BERT 主要用于自然语言理解任务:双向预训练语言模型 + fine-tuning (微调))。
Decoder-only 模型:扩展语言模型的规模可以显著提升其在少样本或零样本时的表现。最成功的模型是自回归语言模型,它的训练方式是根据给定序列中前面的词来生成下一个词。这些模型已被广泛用于文本生成和问答等下游任务。自回归语言模型包括 GPT-3、PaLM 和 BLOOM。具有变革意义的 GPT-3 首次表明,通过提示和上下文学习,可以在少样本/零样本情况下给出合理的结果,并由此展现了自回归语言模型的优越性。此外,还有针对具体任务优化的模型,比如用于代码生成的 CodeX 以及用于金融领域的 BloombergGPT。在 2021 年 GPT-3 出现之后,仅解码器模型经历了爆发式的发展,而仅编码器模型则逐渐淡出了人们的视野。(GPT 主要用于自然语言生成任务:自回归预训练语言模型 + Prompting (指示/提示))。
应用方向
- 自然语言理解:当实际数据不在训练数据的分布范围内,或者训练数据非常少时,可以利用 LLM 出色的泛化能力。
- 自然语言生成:利用 LLM 的能力,为各种应用创造连贯、上下文相关且高质量的文本。
- 知识密集型任务:利用 LLM 中存储的广博知识来处理需要特定专业知识或一般世界知识的任务。
- 推理能力:理解和利用 LLM 的推理能力来提升各种情形中制定决策和解决问题的能力。