想让你的 AI 更懂行?手把手教你用 DeepSeek R1 + Ollama 搭建本地 RAG 应用
嘿,朋友!有没有想过让你的 AI 不仅仅是“会说话”,而是能“引经据典”、基于真实资料来回答问题?这就是 RAG(检索增强生成) 技术的神奇之处。简单说,它就像给 AI 外挂了一个知识库,让它的回答更靠谱、信息更准确。
这篇教程就手把手带你,利用现在很火的 DeepSeek R1 模型和 Ollama 这个工具,在你自己的电脑上搭建一个 RAG 应用。全程本地化,无需担心数据隐私!
动手前的准备:配好环境是第一步
在咱们正式开始“盖楼”之前,得先把“地基”打好——也就是安装 Ollama 并配置好环境。
别担心,过程不复杂。Ollama 的 GitHub 仓库 有超详细的官方指南,这里我帮你提炼下关键步骤:
第 1 步:下载 Ollama
直接去 Ollama 官网下载页面,找到适合你电脑系统(Windows, macOS, Linux 都有)的安装包,下载下来,双击运行就好。
第 2 步:检查下装好了没
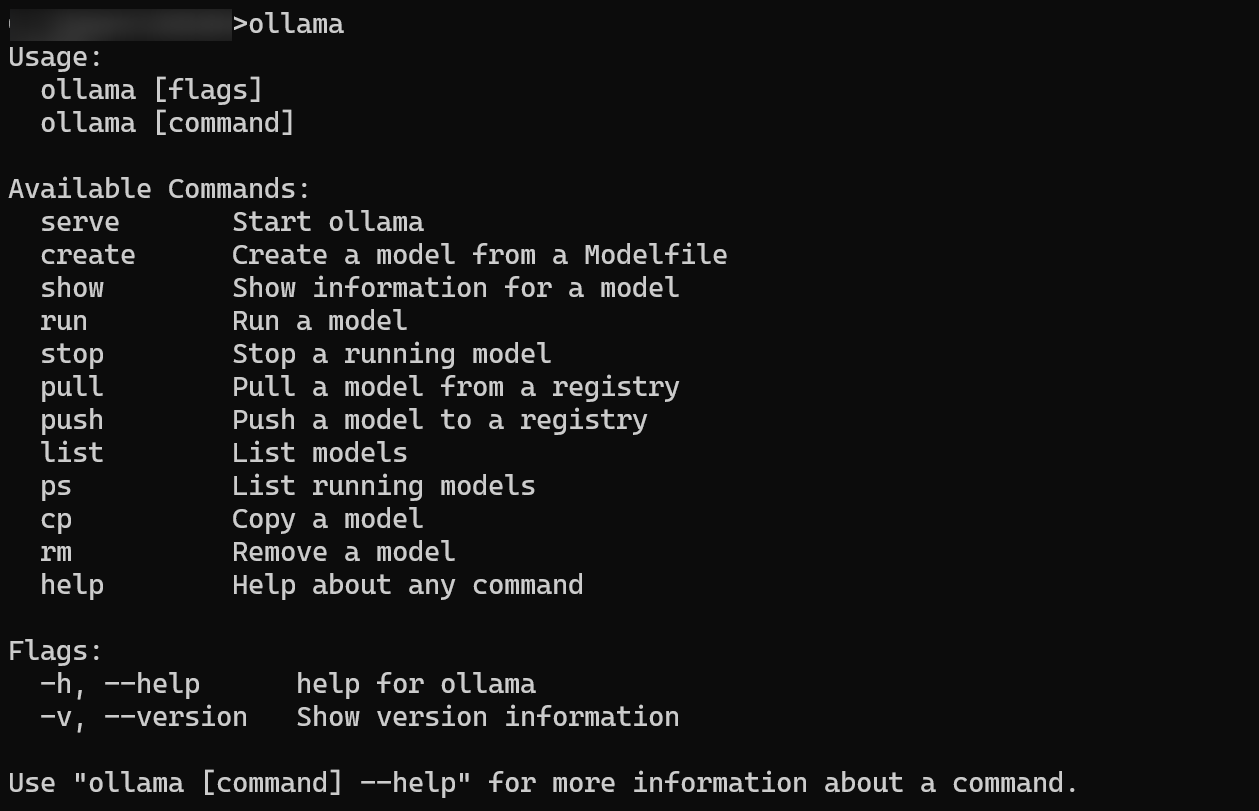
打开你的命令行工具(比如 Windows 的 PowerShell 或 CMD,macOS 的 Terminal),输入 ollama 然后敲回车。如果屏幕上出现了 Ollama 的欢迎信息和命令列表,那就说明 Olla~ma 已经安家落户成功啦!
第 3 步:请“大脑”和“翻译官”就位
我们需要两个模型:一个是负责思考和生成回答的“大脑”(DeepSeek R1),另一个是负责理解文本、把它变成电脑能处理的“向量”的“翻译官”(文本嵌入模型)。
请 DeepSeek R1 大脑: 在命令行里输入下面这行,把它拉取到你本地。
bashollama pull deepseek-r1:1.5b温馨提示: 下载模型可能需要一点时间,网速快慢决定等待时长。如果中途卡壳了,别慌,重新试试命令通常能解决。
请 nomic-embed-text 翻译官: 同样,在命令行输入这行,拉取文本嵌入模型。
bashollama pull nomic-embed-text“文本嵌入模型”是个啥? 简单理解,它就是个能把文字(比如一句话、一段文章)转换成一串数字(向量)的工具。这样,电脑就能通过计算这些数字之间的距离,来判断哪些文字在意思上更接近。后面我们检索资料就靠它了。
第 4 步:让 DeepSeek R1 跑起来!
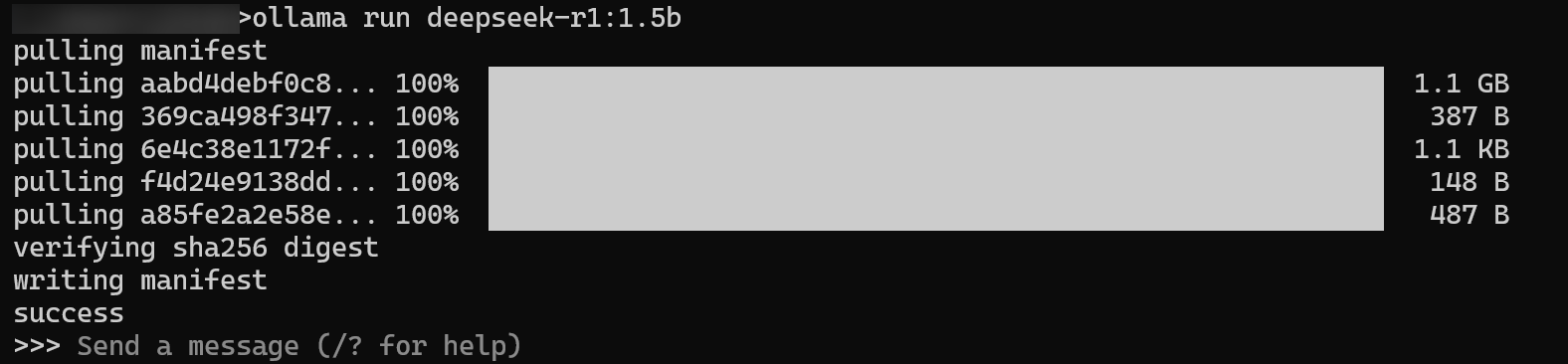
在命令行窗口敲入以下命令,启动 DeepSeek R1 模型服务。
ollama run deepseek-r1:1.5b看到类似下面的界面,就表示模型已经在后台准备好,随时可以接收指令了。

你也可以直接通过
ollama run deepseek-r1:1.5b命令一步到位地拉取并运行模型,非常方便。
注意: 如果你只是想体验下用 Ollama 跑 DeepSeek R1 模型,和它聊聊天,那到这里就够了,后面的步骤是给想搭建完整 RAG 应用的朋友准备的。
第 5 步:安装 Python 工具包
咱们这个 RAG 应用需要用 Python 来“粘合”各个部分。确保你的电脑装了 Python (3.8 或更新版本)。然后,在命令行用 pip 这个工具安装几个必备的库:
# LangChain 核心库,是构建 AI 应用的框架
pip install langchain
# LangChain 社区提供的各种实用工具
pip install langchain_community
# Chroma 数据库,用来存放我们的“知识索引”
pip install langchain_chroma
# 让 LangChain 能和 Ollama 顺利“对话”的桥梁
pip install langchain_ollama好啦,准备工作完成!是不是感觉离目标更近一步了?接下来,我们就正式进入 RAG 应用的搭建环节。
1. 给 AI “喂”点知识——加载并拆分文档
首先,得把我们想让 AI 学习的知识(比如一个 PDF 文件)加载进来,并且切成一小块一小块的,方便后续处理。
# 从 LangChain 社区工具里导入 PDF 加载器
from langchain_community.document_loaders import PDFPlumberLoader
# 从 LangChain 导入文本分割工具
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 指定你的 PDF 文件路径
file = "DeepSeek_R1.pdf"
# 创建一个 PDF 加载器实例,加载文件
loader = PDFPlumberLoader(file)
docs = loader.load() # 这会把 PDF 内容读出来
# 创建一个文本分割器实例
# chunk_size=500 表示尽量按 500 个字符切分
# chunk_overlap=0 表示切分出来的块之间不重叠
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
# 执行切分动作,把长文档变成很多小片段
all_splits = text_splitter.split_documents(docs)这段 Python 代码干了两件事:一是像打开文件一样,用 PDFPlumberLoader 读取了 DeepSeek_R1.pdf 的内容;二是创建了一个“切割机” (RecursiveCharacterTextSplitter),把整个文档按大约 500 个字一块给切开了。
为啥要切分呢? 因为大模型一次能“消化”的文字长度是有限的。把长文档切成小块,既能保证每块信息都能被模型处理,也方便后面我们精确地找到跟问题最相关的那几块内容。
2. 建立“知识索引”——初始化向量存储
有了切好的知识小块,下一步就是把它们变成电脑能理解的“向量”,并存起来,方便快速查找。这里我们用 Chroma 这个“向量数据库”来帮忙。
# 从 LangChain Chroma 库导入 Chroma
from langchain_chroma import Chroma
# 从 LangChain Ollama 库导入 Ollama 嵌入功能
from langchain_ollama import OllamaEmbeddings
# 创建一个 Ollama 嵌入模型的实例,告诉它我们要用 'nomic-embed-text'
local_embeddings = OllamaEmbeddings(model="nomic-embed-text")
# 创建 Chroma 向量数据库
# 把切分好的文档块 (all_splits) 和 嵌入模型 (local_embeddings) 交给 Chroma
# Chroma 会自动调用嵌入模型把文本转成向量,然后存起来
vectorstore = Chroma.from_documents(documents=all_splits, embedding=local_embeddings)看,这里我们先是告诉程序,我们要用之前下载的 nomic-embed-text 模型来做“文本到向量”的转换工作 (OllamaEmbeddings)。然后,调用 Chroma.from_documents,它就会自动地把我们之前切好的 all_splits 里的每一块文本,都通过 local_embeddings 转换成向量,并保存在 Chroma 数据库里。
“向量存储”听起来很高级,其实… 你可以把它想象成一个超级智能的图书馆索引系统。传统索引可能按书名、作者,而向量索引是按“意思”来的。你问一个问题,它能迅速告诉你,“嘿,这几块内容跟你问的意思最像!” 这就是 RAG 检索知识的关键所在。
3. 串联流程——构建处理链 (Chain)
准备工作就绪,是时候把各个零件“组装”起来,形成一个完整的工作流程了。LangChain 提供了一种叫做“链(Chain)”的简洁方式来实现这一点。
# 从 LangChain 核心库导入 输出解析器 和 聊天提示模板
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
# 从 LangChain Ollama 库导入聊天模型
from langchain_ollama import ChatOllama
# 创建一个 Ollama 聊天模型的实例,指定使用 'deepseek-r1:1.5b'
model = ChatOllama(
model="deepseek-r1:1.5b",
)
# 定义一个提示模板,告诉模型要做什么
# {docs} 是一个占位符,后面我们会把找到的文档内容填进去
prompt = ChatPromptTemplate.from_template(
"请根据我提供的这些文档片段,总结一下它们的主要内容: {docs}"
)
# 定义一个辅助函数,方便地把多份文档内容合并成一个字符串
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 构建处理链:
# 1. 把传入的文档列表 (docs) 用 format_docs 函数格式化
# 2. 把格式化后的文档内容填入 prompt 模板
# 3. 把填充好的提示交给 model (DeepSeek R1) 处理
# 4. 用 StrOutputParser 获取模型生成的纯文本回答
chain = {"docs": format_docs} | prompt | model | StrOutputParser()
# 来测试一下!
# 假设我们想问 "DeepSeek 项目的目标是什么?"
question = "What is the purpose of the DeepSeek project?"
# 先在向量数据库里找找相关的文档片段
docs = vectorstore.similarity_search(question)
# 然后把找到的文档片段交给 chain 来处理和总结
chain.invoke(docs)这段代码做了几件事:
- 指定了我们用
deepseek-r1:1.5b作为回答问题的模型 (ChatOllama)。 - 写了一个“指令模板” (
prompt),告诉模型等会儿要基于给它的资料做总结。 - 用
|这个神奇的符号,像流水线一样把“格式化文档”、“填充指令”、“模型处理”、“提取结果”这几个步骤串了起来,形成了一个chain。 - 最后,我们试着问了个问题,先用
vectorstore.similarity_search找到相关资料,再把资料“喂”给chain,让它跑一遍流程,输出总结。
“Chain 表达式”是啥? 它就是 LangChain 里一种组织工作流的方法。你可以想象成用管道 (
|) 把不同的工具(数据加载器、文本处理器、模型、输出格式化工具等)连接起来,数据从一端进去,经过一系列处理,最后从另一端出来。非常灵活!
4. 强强联手——实现带检索的问答 (RAG)
激动人心的时刻到了!现在我们把“找资料”(检索)和“回答问题”(生成)这两大功能合体,打造一个完整的 RAG 系统。
# 从 LangChain 核心库导入一个传递输入的工具
from langchain_core.runnables import RunnablePassthrough
# 定义一个专门给 RAG 用的提示模板
RAG_TEMPLATE = """
你是一个问答助手。请根据下面提供的上下文信息来回答问题。如果你不知道答案,就直接说不知道。回答尽量简洁,不要超过三句话。
<上下文>
{context}
</上下文>
请回答下面的问题:
{question}
"""
# 基于上面的模板创建 RAG 提示实例
rag_prompt = ChatPromptTemplate.from_template(RAG_TEMPLATE)
# 从我们的向量数据库创建一个“检索器”
# 它能根据问题自动去数据库里捞相关文档
retriever = vectorstore.as_retriever()
# 构建最终的问答链 (QA Chain)
qa_chain = (
# 并行处理:
# 1. "context": 用户的问题先经过 retriever 找到相关文档,再用 format_docs 格式化
# 2. "question": 用户的问题直接传递下去
{"context": retriever | format_docs, "question": RunnablePassthrough()}
# 上一步的结果 (包含 context 和 question) 被送入 rag_prompt 模板
| rag_prompt
# 填充好的提示交给 model 处理
| model
# 最后用 StrOutputParser 提取纯文本答案
| StrOutputParser()
)
# 最终测试!
question = "What is the purpose of the DeepSeek project?"
# 直接把问题“喂”给 qa_chain
# 它会自动完成:检索 -> 整理上下文 -> 生成答案 的全过程
qa_chain.invoke(question)这段代码的核心就是构建 qa_chain。你看,它巧妙地把 retriever(检索器)整合了进来。当用户提出 question 时:
retriever先根据question从 Chroma 数据库里找出最相关的文档片段 (context)。- 这些
context和原始的question一起被填入rag_prompt这个更具体的指令模板里。 - 最后,这个包含上下文和问题的完整提示被发送给
model(DeepSeek R1),生成最终的答案。
这就是 RAG 的魔力:它不是凭空回答,而是先“查资料”再“说话”,回答自然就更靠谱了!
大功告成!回顾一下我们的 RAG 之旅
恭喜你!跟着这篇教程,我们一起用 DeepSeek R1 和 Ollama 成功搭建了一个本地运行的 RAG 应用。回顾一下,我们并肩作战,完成了:
- 知识准备: 学会了如何加载 PDF 文档,并把它切分成适合模型处理的小块。
- 建立索引: 利用 Chroma 和 Ollama 的嵌入模型,为知识块建立了高效的“语义索引”。
- 流程编排: 掌握了使用 LangChain 的 Chain 表达式,将数据处理、模型调用等步骤流畅地串联起来。
- RAG 落地: 最终将检索和生成两大模块完美融合,实现了能根据给定文档回答问题的智能系统。
现在,你拥有了一个完全跑在你本地电脑上的、具备“学习”能力的 AI 应用雏形。不妨动手试试用你自己的文档来构建知识库,看看它能带来什么惊喜吧!
下一步探索? 如果你想让更多人方便地使用你的 RAG 应用,可以考虑用 Streamlit 或 FastAPI 这样的工具,把它打包成一个网页服务。想象一下,做一个能回答你专业领域文档内容的智能助手,是不是很酷?
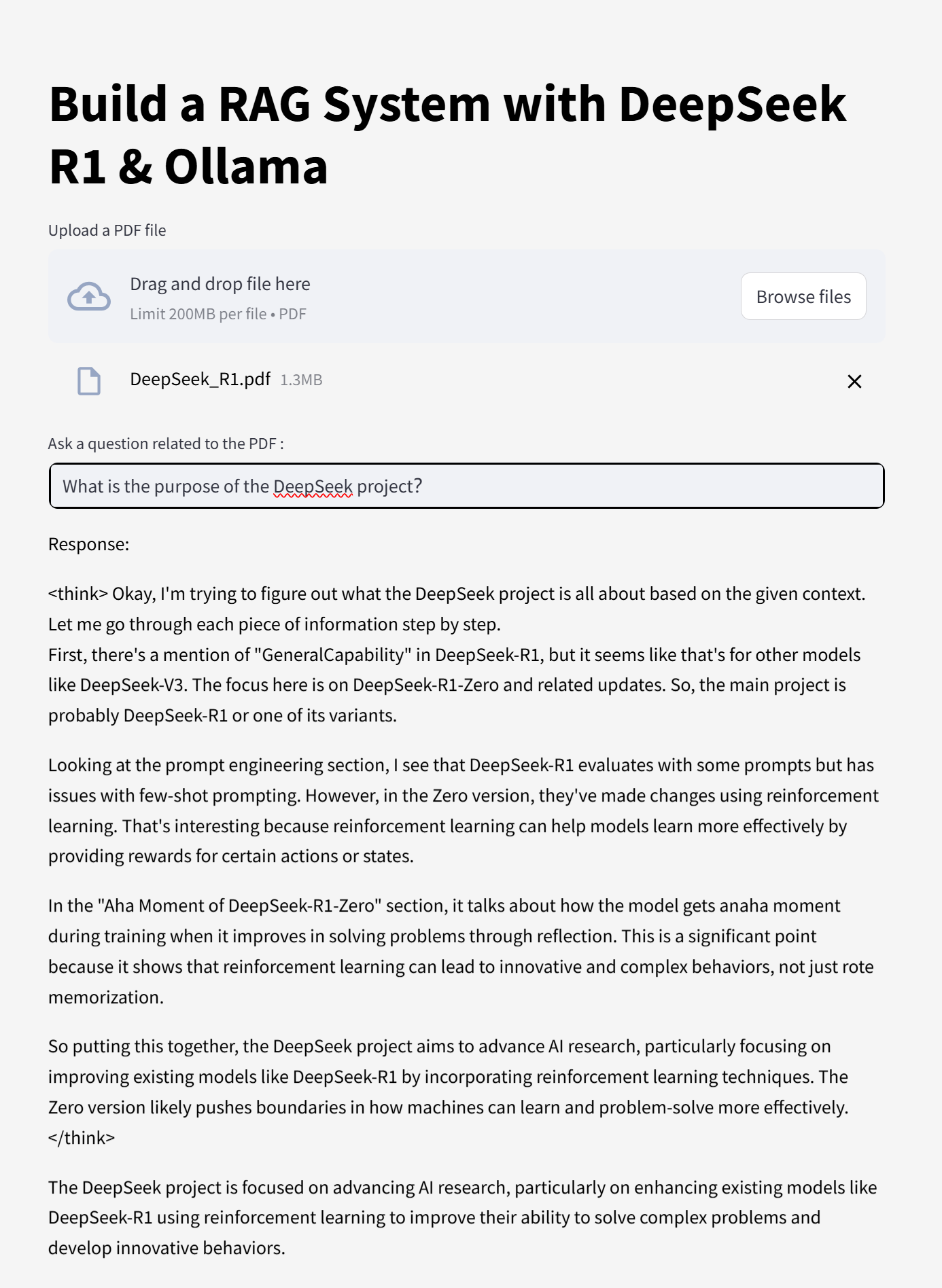
我们还在代码仓库里为你准备了一个可以直接运行的 Web 应用示例 app.py。记得,在运行它之前,要先确保 Ollama 服务已经在后台启动了哦!
启动这个 app.py 后,在浏览器里就能看到一个简单的对话界面,让你和你的本地 RAG 应用互动起来!
玩得开心!探索 AI 的世界,乐趣无穷!