给 Ollama 模型来点“私人订制”?Modelfile 玩法大揭秘!
想不想让 Ollama 不仅仅是运行别人打包好的模型?想不想自己动手,把网上淘来的各种模型(比如 GGUF 格式的,或者 PyTorch/Safetensors 格式的)导入 Ollama,甚至给它们加点“个性”(自定义 Prompt)?
那你就来对地方了!这篇指南,就是带你解锁 Ollama 的 Modelfile 这个强大工具。有了它,你就能像搭积木一样,组合、配置,甚至“改造”模型,让它们更听你的话!
咱们今天主要研究这几种玩法:
- 直接“喂” GGUF 文件: 这是最省事儿的一种。
- 试试 PyTorch 或 Safetensors 文件: 稍微进阶一点,看看能不能直接用。
- 终极大法:自己动手转换模型: 搞定各种来源的模型。
- 给模型“洗脑”:自定义 Prompt: 让 AI 扮演你想要的角色!
准备好了吗?开始我们的模型 DIY 之旅!
玩法一:直接用 GGUF 文件『喂』给 Ollama
GGUF 这玩意儿是啥?
简单说,GGUF (GPT-Generated Unified Format) 就是一种专门给大语言模型打包的文件格式。它的好处多多:
- 跨平台小能手: 不管你是 Windows、Mac 还是 Linux,它都能用。
- 身材灵活: 支持各种“压缩”(量化)技术,能把大模型变小,省地方也省计算资源。
- 方便分享: 一个文件就搞定,传来传去很方便。
你可以把它想象成一个通用接口的模型文件,方便大家使用。
怎么把 GGUF 文件导入 Ollama?
先搞到
.gguf文件: 咱们拿 Qwen2-0.5B 这个模型练手。你可以从这个链接下载它的 GGUF 文件:https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-0.5B-gguf/resolve/main/Qwen2-0.5B.Q3_K_M.gguf?download=true下载下来后,把它放到一个你找得到的地方。为了整洁,最好专门建个文件夹,把 Modelfile 和模型文件放一起。比如像这样整理:
我的Ollama实验/ ├── 1-从gguf导入/ <-- 咱们现在在这个文件夹 │ ├── Modelfile <-- 等下要创建的文件 │ └── Qwen2-0.5B.Q3_K_M.gguf <-- 下载好的模型文件 ├── 2-safetensors导入/ │ └── ... ├── 3-模型直接导入/ │ └── ... └── 4-自定义Prompt/ └── ...- 小提示: 这篇教程用到的所有代码和文件,你都可以在 这里 (notebook/C3 目录) 找到。
创建
Modelfile文件: 在刚才放.gguf文件的那个文件夹里(比如1-从gguf导入/),新建一个没有扩展名的文件,名字就叫Modelfile。用记事本或者其他文本编辑器打开它,写上这行:ModelfileFROM ./Qwen2-0.5B.Q3_K_M.gguf这行代码的意思很简单,就是告诉 Ollama:“嘿,从我旁边的这个
.gguf文件里加载模型!”让 Ollama 创建模型: 打开你的命令行终端 (CMD 或 PowerShell),切换到
Modelfile文件所在的那个目录 (比如cd 我的Ollama实验/1-从gguf导入/),然后敲这个命令:bashollama create my-qwen-gguf -f Modelfilemy-qwen-gguf是你给这个新模型起的名字,可以随便改。-f Modelfile告诉 Ollama 去读当前目录下的Modelfile文件来创建模型。
跑起来试试! 模型创建成功后,就可以像运行其他 Ollama 模型一样来玩了:
bashollama run my-qwen-gguf看看是不是能跟它聊天了?

玩法二:试试 PyTorch 或 Safetensors 文件
Safetensors 又是什么?
这是一种更现代、更安全的模型权重存储格式。相比老的 pickle 格式,它不容易藏“病毒”(恶意代码),加载速度也更快。现在很多新模型都用它。
Ollama 能直接吃 Safetensors 吗?
理论上,Ollama 对某些特定“骨架”(架构)的模型,比如基于 Llama、Mistral、Gemma 的,可以直接从包含 Safetensors 文件的文件夹导入。
- 友情提示: 这个功能 Ollama 官方还在打磨中,不一定保证对所有模型都好用。下面的步骤仅供参考,如果遇到问题,可能还是得用后面的“终极大法”(转换成 GGUF)。
尝试步骤:
下载模型文件 (以 Llama-3 为例): 你需要用到 Hugging Face 官方提供的工具来下载。先装一下:
bashpip install huggingface_hub然后用 Python 代码下载模型。你需要一个 Hugging Face 账号的访问令牌 (Access Token),后面会讲怎么获取。
pythonfrom huggingface_hub import snapshot_download # 注意:这里用的是 unsloth 提供的 4bit 量化版 Llama-3,体积小点 model_id = "unsloth/llama-3-8b-bnb-4bit" # 把 <YOUR_ACCESS_TOKEN> 换成你自己的令牌 # 它会下载到当前目录下的 llama-3-8b-bnb-4bit 文件夹里 snapshot_download( repo_id=model_id, local_dir="llama-3-8b-bnb-4bit", local_dir_use_symlinks=False, revision="main", use_auth_token="<YOUR_ACCESS_TOKEN>")创建
Modelfile: 在包含llama-3-8b-bnb-4bit这个文件夹的上一级目录(比如2-safetensors导入/目录)创建Modelfile,内容是:ModelfileFROM ./llama-3-8b-bnb-4bit注意,这里
FROM指向的是包含模型文件的文件夹。让 Ollama 创建模型: 在
Modelfile所在的目录运行:bashollama create my-llama3-sft -f Modelfile尝试运行:
bashollama run my-llama3-sft祈祷它能成功运行吧!🤞
玩法三:终极大法 —— 自己动手转换模型 (搞定各种来源)
有时候,我们从 Hugging Face 或其他地方下载的模型,Ollama 不认识,或者直接导入效果不好。这时候,就得祭出“终极大法”:先把模型转换成 Ollama 最喜欢的 GGUF 格式,再用玩法一的方法导入。
这个过程稍微有点折腾,主要分几步:
- 从 Hugging Face 把模型完整下载下来。
- 请出转换神器
llama.cpp,把模型变成 GGUF。 - (可选但推荐) 用
llama.cpp给模型“瘦身”(量化)。 - 最后用玩法一的方式创建并运行。
3.1 从 Hugging Face 下载模型
直接用网页下载或 git clone 大模型容易失败(太大,网络容易中断)。我们还是用 Python 脚本来下,比较稳妥。
先搞定 Hugging Face 访问令牌 (Access Token):
- 登录你的 Hugging Face 账号,点右上角头像,进 "Settings"。
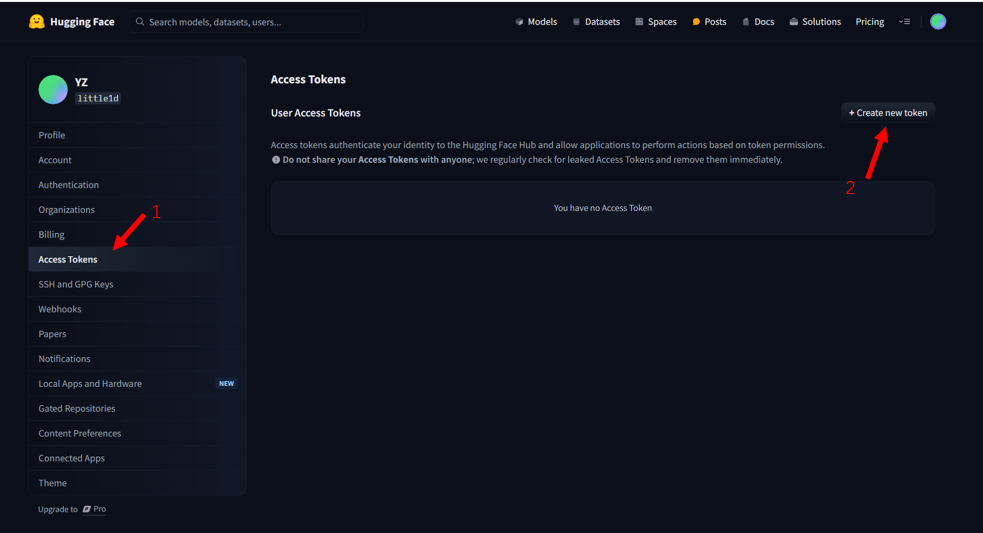
- 左边菜单栏找到 "Access Tokens"。
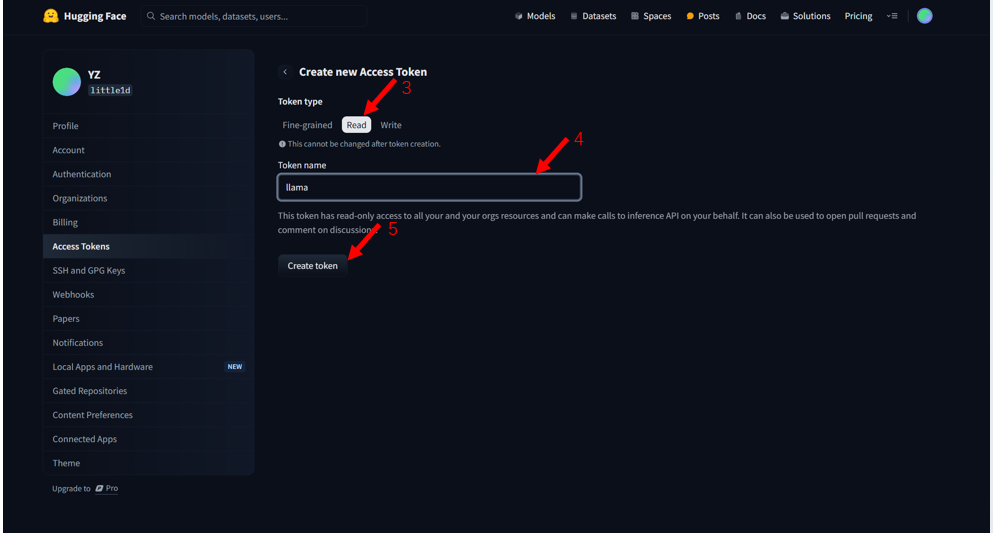
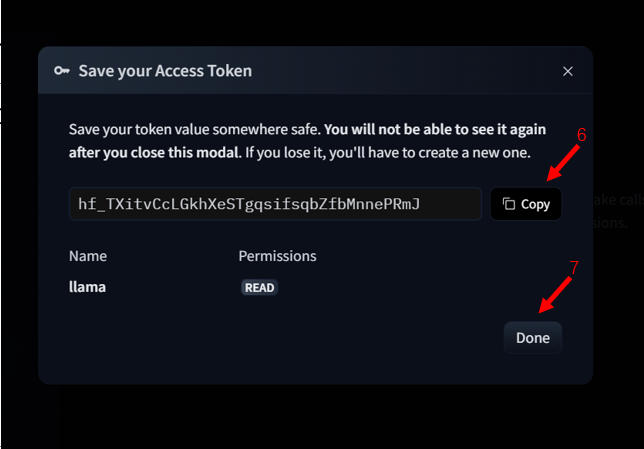
- 点 "New token" 创建一个新令牌。权限 (Role) 至少需要 "read"。给它起个名字,然后点 "Generate a token"。创建后马上把令牌复制下来存好,它只显示一次!
用 Python 下载模型 (继续用 Qwen-0.5B 举例):
把下面的代码保存成一个 Python 文件(比如 download_model.py),然后把 <YOUR_ACCESS_TOKEN> 换成你刚才复制的令牌。
from huggingface_hub import snapshot_download
model_id = "Qwen/Qwen1.5-0.5B" # Hugging Face 上的模型 ID
# 下载到当前目录下的 Qwen-0.5b 文件夹
snapshot_download(
repo_id=model_id,
local_dir="Qwen-0.5b",
local_dir_use_symlinks=False,
revision="main",
use_auth_token="<YOUR_ACCESS_TOKEN>") # 把这里换成你的令牌!
print(f"模型 {model_id} 下载完成,保存在 Qwen-0.5b 文件夹中。")运行这个 Python 脚本 (python download_model.py)。它会把模型文件下载到 Qwen-0.5b 文件夹里。耐心等它下完。
3.2 用 llama.cpp 进行转换
llama.cpp 是个很牛的项目,能让你在普通 CPU 上跑大模型,而且它也提供了超好用的模型格式转换工具。
把
llama.cpp代码“克隆”到本地: 在你的工作目录下(比如3-模型直接导入/),打开终端,运行:bashgit clone https://github.com/ggerganov/llama.cpp.git这会下载
llama.cpp的所有代码到llama.cpp文件夹。安装
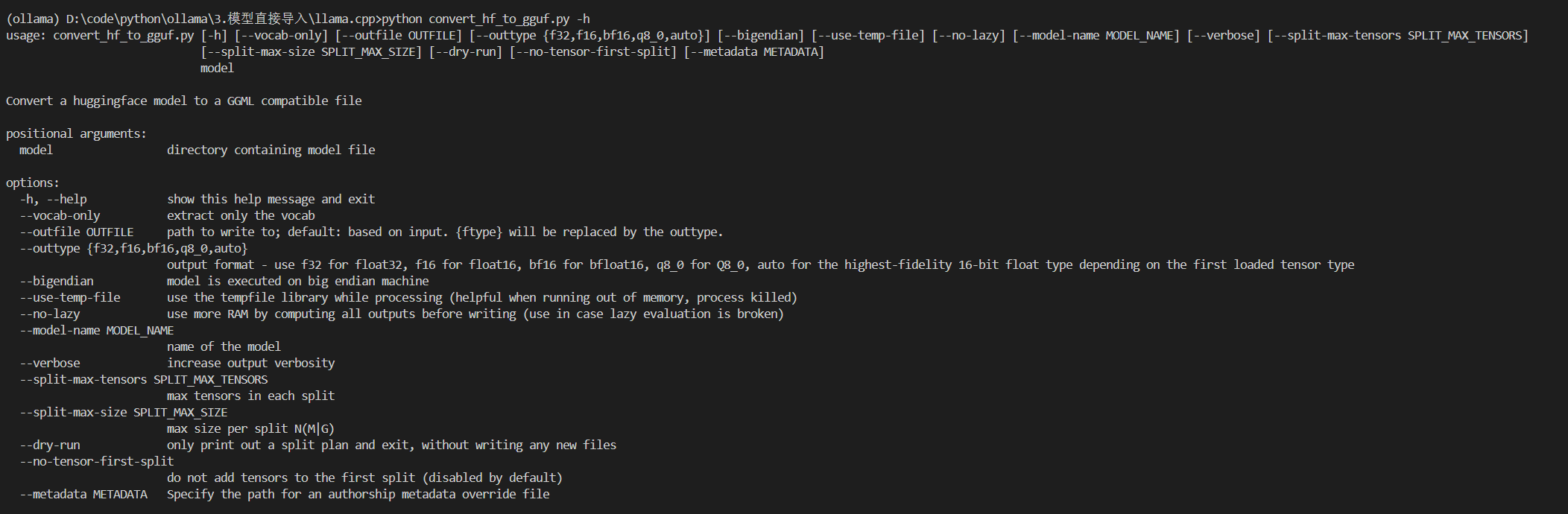
llama.cpp的 Python 依赖: 转换脚本是用 Python 写的,需要装些库。最好给它创建一个独立的 Python 环境(用 conda 或 venv),避免和你系统里其他的库冲突。bashcd llama.cpp # 进入 llama.cpp 文件夹 pip install -r requirements.txt # 安装需要的库 python convert_hf_to_gguf.py -h # 测试一下转换脚本能不能运行如果最后一条命令输出了一堆帮助信息,说明环境没问题了。
开始转换! 还在
llama.cpp目录下,运行下面的命令,把我们之前下载的Qwen-0.5b模型转换成 GGUF 格式:bash# ../Qwen-0.5b 指向我们下载的模型文件夹 (注意相对路径) # --outfile 指定输出的 GGUF 文件名 # --outtype f16 指定输出精度为 float16 (常用的精度) python convert_hf_to_gguf.py ../Qwen-0.5b --outfile Qwen_instruct_0.5b.gguf --outtype f16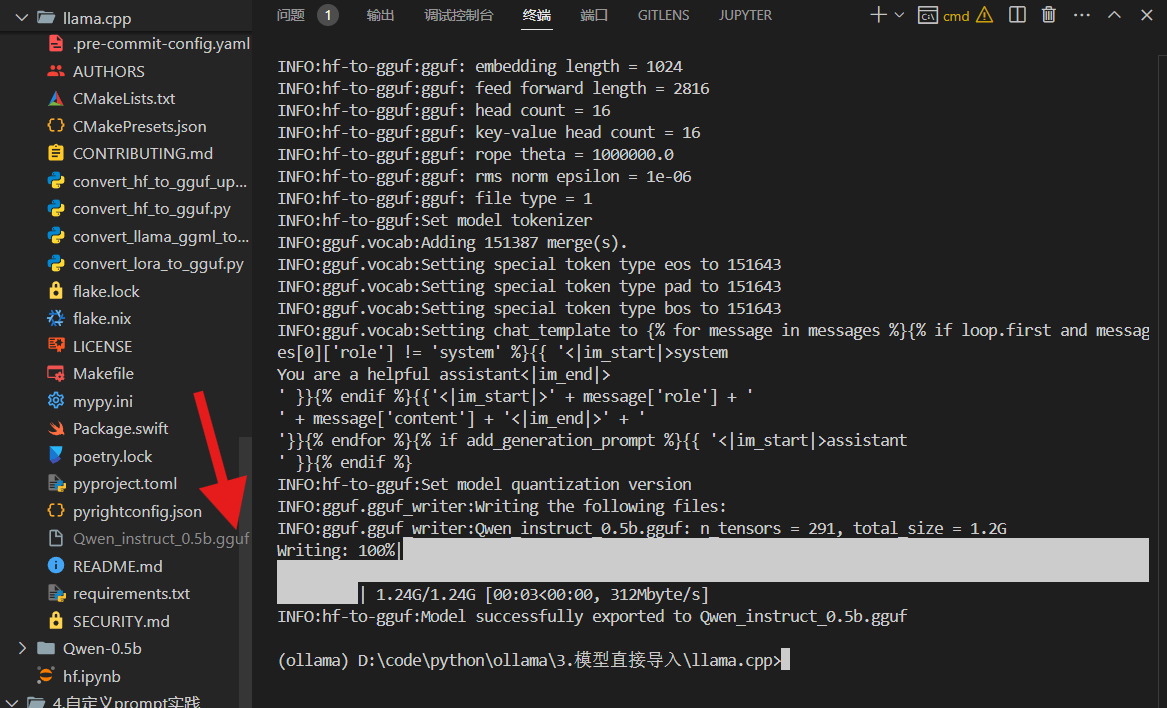 很快,你应该就能在
很快,你应该就能在 llama.cpp文件夹里看到一个新文件:Qwen_instruct_0.5b.gguf。搞定!
3.3 (可选) 给模型“瘦身” —— 量化
原始的 f16 (float16) 精度模型可能还是有点大。我们可以用 Ollama 自带的功能,在创建模型的时候顺便给它做个“量化”,把它压缩得更小。量化会损失一点点精度,但通常能大幅减小体积和内存占用,让模型跑得更快。
准备
Modelfile: 先把刚才生成的Qwen_instruct_0.5b.gguf文件,从llama.cpp文件夹移动或复制到你的工作目录(比如3-模型直接导入/)。然后,在这个目录下创建Modelfile,内容还是:ModelfileFROM ./Qwen_instruct_0.5b.gguf创建并量化模型: 在
Modelfile所在的目录(比如3-模型直接导入/)打开终端,运行:bash# -q Q4_K_M 是告诉 Ollama 使用 Q4_K_M 这种量化方法 # my-qwen-quantized 是我们给量化后的模型起的名字 ollama create -q Q4_K_M my-qwen-quantized -f ./Modelfile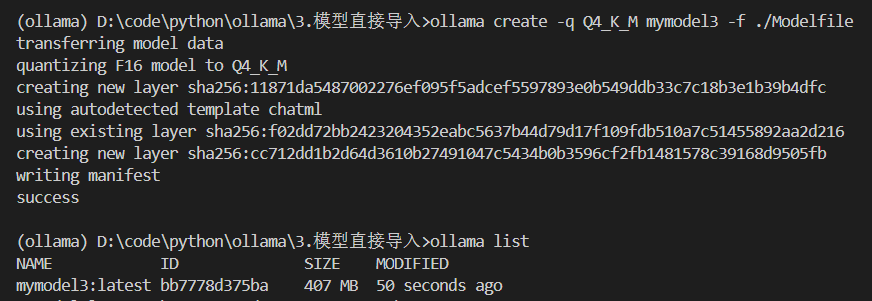 Ollama 会读取 GGUF 文件,进行量化,然后创建一个名为
Ollama 会读取 GGUF 文件,进行量化,然后创建一个名为 my-qwen-quantized的新模型。这个过程可能需要一点时间。- 量化方法小科普:
Q4_K_M是一种常用的 4-bit 量化方法,平衡了压缩率和性能损失。你也可以试试其他的量化级别,比如Q5_K_M(精度高一点,体积大一点) 或者Q3_K_S(体积更小,精度损失可能更大)。具体选哪个看你的需求和机器性能。
- 量化方法小科普:
3.4 运行和 (如果你想) 上传
现在,你就可以运行这个你自己转换并量化好的模型了:
ollama run my-qwen-quantized感觉怎么样?是不是很酷!
想把你做好的 GGUF 模型分享到 Hugging Face?
如果你觉得你转换或量化好的模型很不错,想分享给别人,或者备份到自己的 Hugging Face 仓库,可以用下面的 Python 脚本(需要 huggingface_hub 库):
from huggingface_hub import HfApi
import os
# 确保你的令牌有 "write" 权限!
HF_WRITE_TOKEN = "<YOUR_HF_WRITE_ACCESS_TOKEN>" # 换成你的写权限令牌
# 把 "your_hf_username/your_repo_name" 换成你自己的用户名和想创建的仓库名
repo_id = "your_hf_username/My-Awesome-Qwen-GGUF"
api = HfApi()
# 创建一个仓库 (如果不存在的话)
api.create_repo(
repo_id,
exist_ok=True,
repo_type="model",
token=HF_WRITE_TOKEN, # 注意这里用 token 参数
)
# 找到当前文件夹下所有的 .gguf 文件并上传
print(f"开始上传 .gguf 文件到 {repo_id}...")
for filename in os.listdir("."):
if filename.endswith(".gguf"):
print(f"正在上传 {filename} ...")
api.upload_file(
path_or_fileobj=os.path.join(".", filename), # 本地文件路径
path_in_repo=filename, # 在仓库里的文件名
repo_id=repo_id,
repo_type="model",
token=HF_WRITE_TOKEN, # 再次提供令牌
)
print("所有 .gguf 文件上传完成!")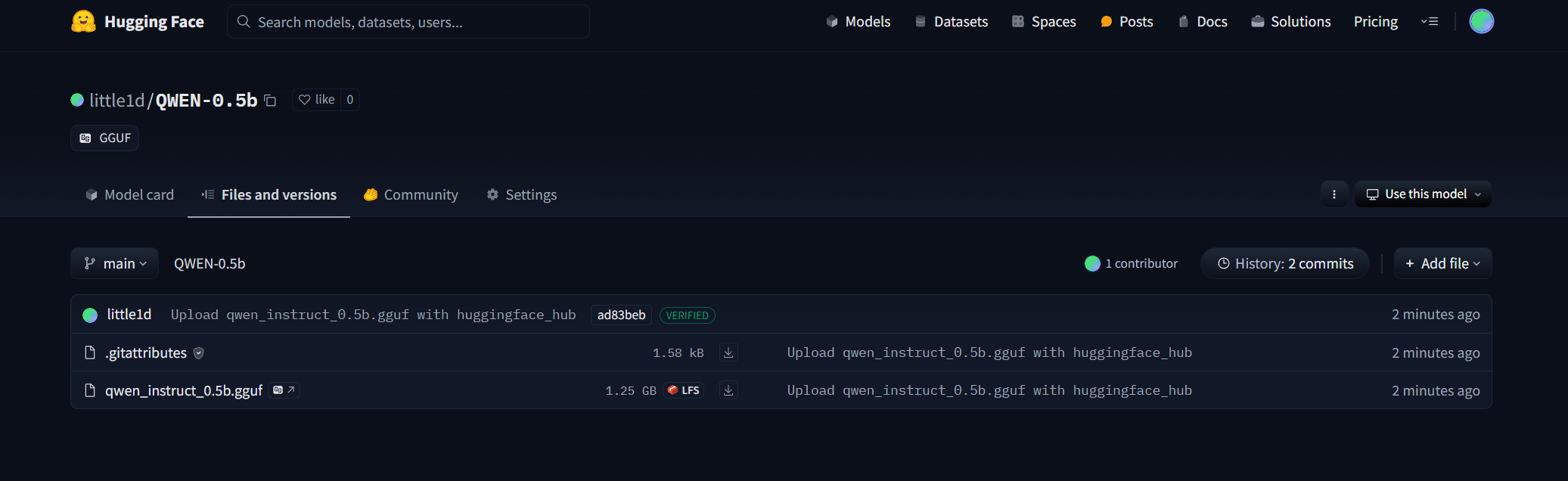 这样,别人就能在 Hugging Face 上找到并下载你做的 GGUF 模型啦!
这样,别人就能在 Hugging Face 上找到并下载你做的 GGUF 模型啦!
玩法四:给模型“洗脑” —— 自定义 Prompt
想让模型扮演特定角色?或者给它设定一些默认的行为准则?用 Modelfile 的 SYSTEM 指令就能轻松搞定!
来,我们把 Llama 3.1 变成马里奥大叔!
创建
Modelfile: 在你的工作目录(比如4-自定义Prompt/)下创建Modelfile,写入:Modelfile# 基于哪个模型来改?这里用官方的 llama3.1 FROM llama3.1 # 调整参数,让它更有“创意”一点 # temperature 越高,回答越随机;越低,越固定。1 是比较高的值。 PARAMETER temperature 1 # 设置它能“记住”多少上下文(token 数量) PARAMETER num_ctx 4096 # 关键来了!设置系统提示 (System Prompt) # 告诉模型:“你现在是超级马里奥兄弟里的马里奥,扮演一个助手。” SYSTEM """It's-a me, Mario! I'm-a here to help you with your questions! Wahoo! Just-a remember, I might talk-a like-a this!"""FROM: 指定基础模型。Ollama 会先确保你有这个模型,没有的话会自动下载。PARAMETER: 用来调整模型的各种参数,比如temperature(温度/创造性) 和num_ctx(上下文长度)。SYSTEM: 这就是你的“系统指令”,模型在每次对话开始时都会默认记住这段话,从而影响它的行为和说话风格。你可以尽情发挥创意!
创建这个“马里奥版”模型: 在
Modelfile所在目录运行:bashollama create mario-llama -f ./Modelfile 这个过程可能需要点时间,因为它要基于
这个过程可能需要点时间,因为它要基于 llama3.1创建一个新的模型层。
检查一下模型列表: 运行
ollama list,看看是不是多了一个叫mario-llama的模型?
和马里奥聊天吧!
bashollama run mario-llama 试试问他点问题,看看他是不是真的用马里奥的口音回答你?Wahoo!
试试问他点问题,看看他是不是真的用马里奥的口音回答你?Wahoo!
Ollama 和 Modelfile 的潜力远不止于此,你可以继续探索更多参数、更复杂的指令组合。快去动手实践,打造属于你自己的、独一无二的本地 AI 助手吧!