TIP
RAG: 指的是一种大语言模型,它在运行时(而不是预训练时)使用外部数据存储。
简单来说,RAG 就是让 LLM 在回答问题之前,先从外部知识库里“查阅资料”。
RAG 的核心概念
根据 A Survey on Retrieval-Augmented Text Generation 这篇论文,RAG 是深度学习和传统检索技术的结合。在生成式大模型时代,RAG 有以下优势:
- 知识库与模型分离: 知识不是存储在模型参数里,而是以明文形式存储在数据库中,更加灵活。
- 生成任务简化: LLM 的任务从生成文本变成了总结文本,降低了生成难度,也提高了生成结果的可信度。
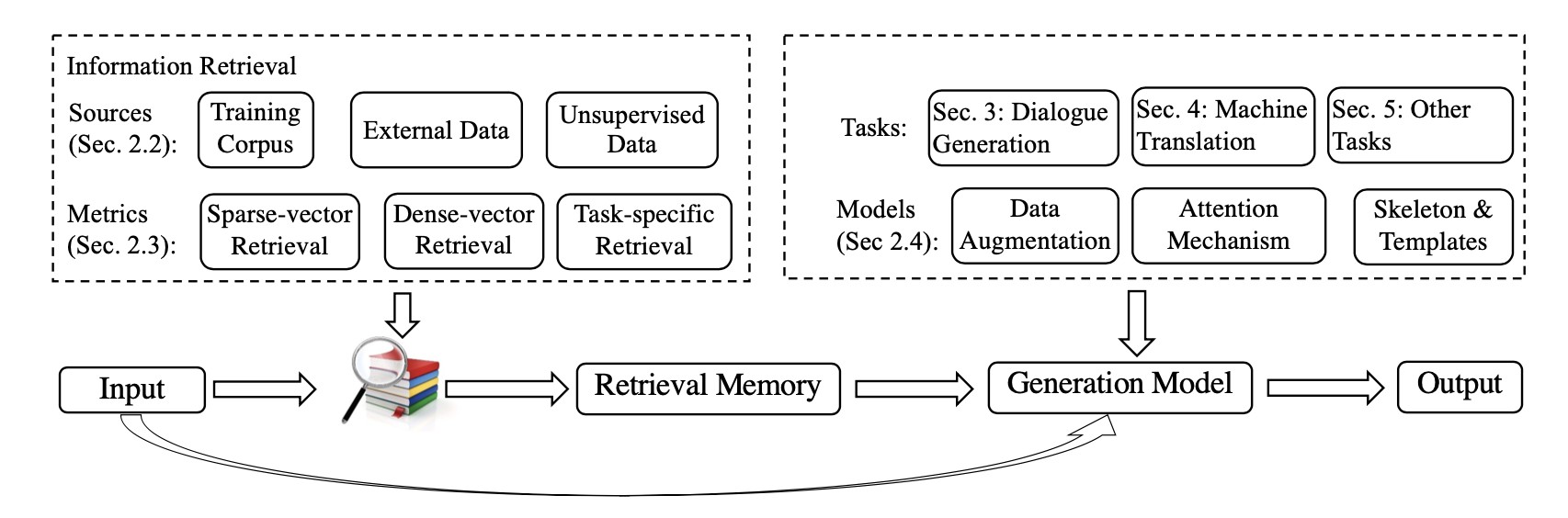
如图所示,RAG 范式包含三个关键组成部分:
- Retrieval Source(检索来源): 从哪里获取知识。
- Retrieval Metric(检索指标): 如何找到相关的知识。
- Integration Method(集成方法): 如何将检索到的知识融入到 LLM 的生成过程中。
RAG 的数学表示
传统的文本生成可以用这个公式表示:
$$\boldsymbol{y}=f(\boldsymbol{x})$$
其中,$\boldsymbol{x}$ 是输入的文本, $f$ 是模型, $\boldsymbol{y}$ 是模型输出的文本。
而 RAG 可以用这个公式表示:
$$\boldsymbol{y}=f(\boldsymbol{x}, \boldsymbol{z}), \boldsymbol{z} = {(\boldsymbol{x}^\gamma, \boldsymbol{y}^\gamma)}$$
其中,$\boldsymbol{x}$ 是输入的文本,$\boldsymbol{z}$ 是知识库,$f$ 是模型,$\boldsymbol{x}^\gamma$ 是用来检索知识的 key,$\boldsymbol{y}^\gamma$ 是与模型输出相关的知识。
检索来源的类型
- Training Corpus(训练语料): 直接使用标注好的训练数据作为外部知识。
- External Data(外部数据): 提供训练数据之外的外部知识作为检索来源,例如与任务相关的领域数据,帮助模型快速适应新领域。
- Unsupervised Data(无监督数据): 前两种知识源都需要人工标注来对齐“检索依据-输出”,而无监督知识源可以直接使用未标注/未对齐的知识作为检索来源。
检索指标的类型
- Sparse-vector Retrieval(稀疏向量检索): 适用于稀疏向量的度量方法,例如 TF-IDF, BM25 等,这些方法主要关注关键词的匹配。
- Dense-vector Retrieval(稠密向量检索): 适用于稠密向量的度量方法,例如文本相似度,这些方法能够捕捉更深层的语义信息。
- Task-specific Retrieval(特定任务检索): 在通用度量方法中,得分高并不一定代表召回的知识准确。因此,有研究者提出基于特定任务优化的召回度量方法,以提高准确率。
集成方法的类型
- Data Augmentation(数据增强): 直接将用户输入的文本和检索到的知识文本拼接起来,然后输入到文本生成模型中。
- Attention Mechanisms(注意力机制): 引入额外的 Encoder,对用户输入文本和知识文本进行注意力编码,然后再输入到文本生成模型中。
- Skeleton Extraction(骨架抽取): 前两种方法都是通过文本向量化的隐式方法来抽取知识重点片段,而 Skeleton Extraction 方法则可以显式地完成类似的工作。
在 RAG 模式下,AI 应用的范式发生了转变,从传统的 Pre-training + Fine-tune 变成了 Pre-training + Prompt。这种转变简化了模型训练的工作量,降低了 AI 的开发和使用门槛,同时也使得 Retriveval + Generation 成为可能。

为什么要用 RAG?
即使大模型本身已经很强大,Fine-tune 也可以补充领域知识,为什么 RAG 仍然如此重要呢?
解决幻觉问题: 尽管大模型的参数量很大,但与人类的知识总量相比,仍然有很大的差距。因此,大模型在生成内容时,可能会捏造事实,产生“幻觉”(如 @sec-hallucination 所述)。RAG 通过搜索召回相关领域知识,作为知识补充,可以有效缓解这个问题。
解决语料更新的时效性问题: 大模型的训练数据存在时间截止的问题。虽然可以通过
Fine-tune为大模型加入新的知识,但训练成本和时间仍然是一个难题:通常需要大量的计算资源,而且难以做到天级别更新。在 RAG 模式下,向量数据库和搜索引擎的数据更新更加容易,有助于保证业务数据的实时性。解决数据泄露问题: 虽然
Fine-tune可以增强 LLM 在特定领域的处理能力,但用于Fine-tune的领域知识可能包含个人或公司的机密信息,这些数据可能会通过模型泄露[^1]。RAG 可以通过增加私有数据存储的方式,提高用户数据的安全性。