揭秘 LLM 的“乐高积木”:Tokens 到底是个啥玩意儿?
你想知道大语言模型 (LLM) 是怎么读懂我们的话,还能写出文章、代码的吗?背后有个关键的秘密武器,那就是 Tokens (分词)。
你可以把 Tokens 想象成 LLM 世界里的 “乐高积木”。模型不是一个字一个字地看文本,而是先把文本拆成一块块的“积木”,然后通过理解和排列这些积木来学习、理解和生成内容。
这些“积木”可能是一个字母、一个完整的单词、一个词组(比如“北京”),甚至是一小段代码。具体怎么拆,取决于模型使用的 “拆分大法” (Tokenization 算法)。不同的算法,拆出来的“积木”大小和样子也可能不一样。这个“拆分大法”和负责执行拆分的 “拆分器” (Tokenizer),可以说是 LLM 的地基。
在拆分过程中,每一块“乐高积木”(Token)都会得到一个独一无二的 “身份证号码” (ID)。模型在内部处理的,其实就是这些数字 ID。
眼见为实:用 OpenAI Tokenizer 工具“玩”一下 Tokens
想亲眼看看文本是怎么被拆成“积木”的?OpenAI 提供了一个超方便的在线 Tokenizer 工具。你可以把一段话输进去,看看它在 GPT 模型眼里变成了哪些 Tokens。
试试英文:

拆分结果出来啦:
INFO

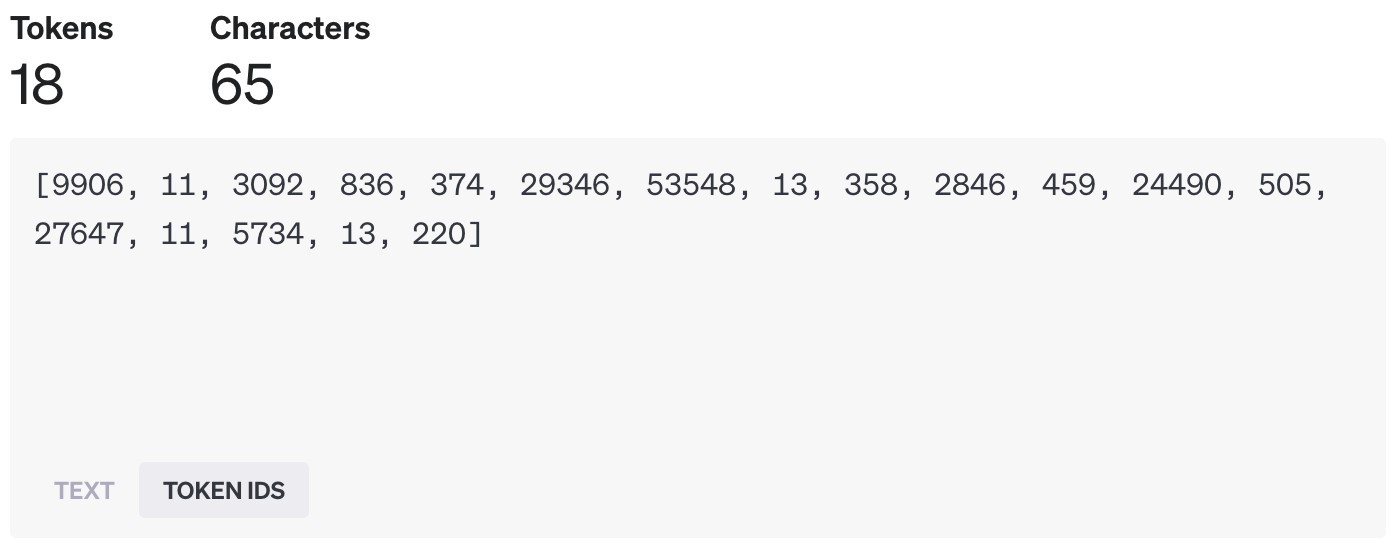
用 OpenAI GPT-4 模型拆分英文的结果
在 OpenAI 的模型里,经验上讲,一个 Token 大概相当于 4 个英文字母,或者说大半个英文单词。
试试中文:
中文拆分起来稍微有点“个性”。

看看结果:
INFO

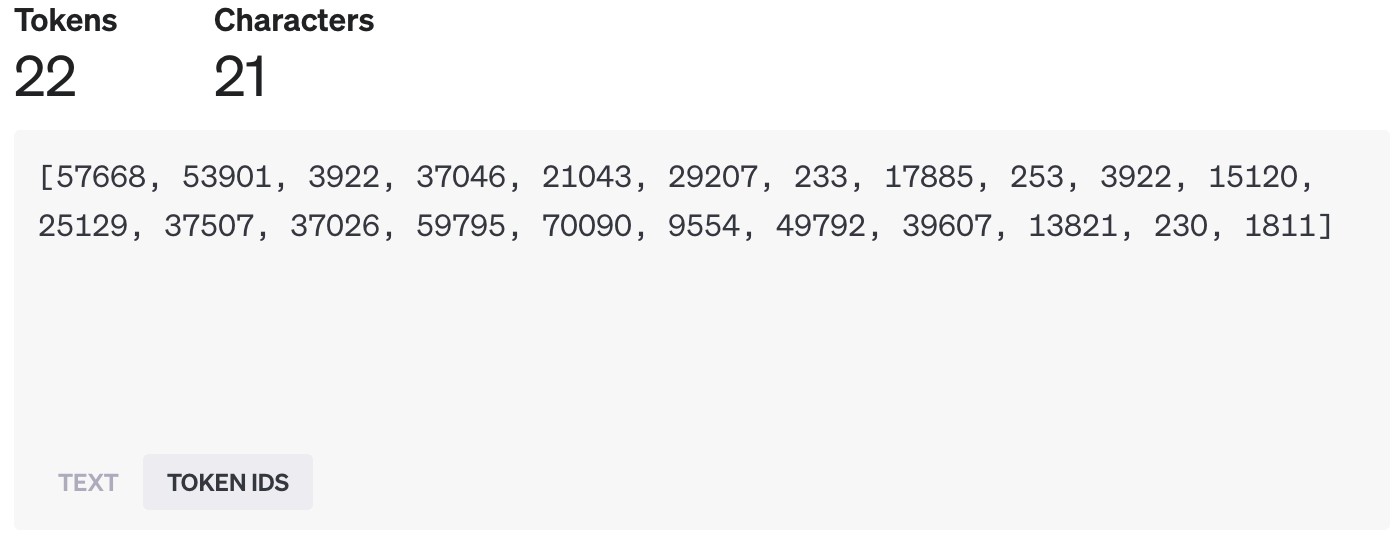
用 OpenAI GPT-4 模型拆分中文的结果
咦?咋好像有乱码?
别慌!这不是真的乱码。这其实是 Tokenizer 工具的一个“视觉小插曲”。有些中文字符比较特殊,或者模型内部处理时,一个汉字可能被拆成了好几个部分(对应多个 Token ID),工具在显示时把每个部分的底层字节都展示出来了,看起来就像乱码。重点是理解:中文也被成功拆分成了 Tokens,每个 Token 也有自己的 ID。
而且你会发现,中文不一定是“一字一 Token”。比如上面的“北京”,就被视为一整块“积木”,ID 是 70090。
想在代码里用这个“拆分器”?
- Python 用户: 推荐使用
tiktoken这个库。 - JavaScript 用户: 可以试试
dqbd/tiktoken这个库。
“拆分大法”哪家强?常见的 Tokenization 算法
把文本变成 Tokens 的过程,就叫 Token 化 (Tokenization)。市面上主流的“拆分大法”有这么几种:
1. BPE (字节对编码 - Byte Pair Encoding)
你可以把它想象成一种**“智能合并”**大法。
- 原理: 最开始,它是一种压缩数据的方法。思路是找出文本里最常一起出现的“邻居”(比如字母
a和a经常一起出现变成aa),然后把这对邻居合并成一个新的符号(比如X代表aa)。不断重复这个过程,就能把常用的词组或单词片段合并成一个 Token。 - 进化版 (BBPE): 后来有人把它升级了,不光看字母,连底层的字节都看,这样处理各种语言(包括中文)和特殊符号就更方便了。OpenAI 的 GPT 系列模型用的就是这种 BPE 算法。
- 优点: 能很好地处理没见过的新词或罕见词(因为它能拆成更小的片段),还能让文本表示更紧凑。模型也能通过组合现有积木来创造新词。
- 权衡: BPE 的“积木仓库”(词汇表)越大,模型能表达的就越丰富,但同时也越“吃”内存和算力。所以要找到一个平衡点。
2. WordPiece
这个和 BPE 很像,也是从小词汇表开始不断合并。
- 关键区别: BPE 看谁俩出现频率高就合并谁;WordPiece 更看重合并后的**“信息量”或者说“意义凝聚度”**(可以理解为看哪两个片段合并后,作为一个整体最有意义、最能代表一个概念)。BERT 这些 Google 开发的模型常用这个。
- 特点: 在平衡词汇表大小和处理未知词(OOV 问题)方面做得不错,但有时候可能会把词切得有点奇怪,而且对拼写错误比较敏感。
3. Unigram Language Model (ULM)
这个思路反过来,有点像搞**“末位淘汰”**。
- 原理: 先准备一个超级大的候选“积木”列表,然后评估如果把某个“积木”去掉,对整个模型的理解能力损失有多大。损失小的就淘汰掉,损失大的(说明它很重要)就留下来。
- 特点: 对噪声数据有一定学习能力,但效果好坏很大程度上取决于一开始给的那堆候选“积木”质量如何。
Tokens = 金钱 + 性能:为什么你要关心它?
你用了多少 Tokens,直接关系到你使用 LLM 的成本和速度!
- 资源消耗: 模型处理的 Tokens 越多,就需要越多的内存(显存)和计算能力(CPU/GPU 时间)。
- 使用成本: 很多 LLM 服务是按 Token 数量收费的(包括输入和输出)。用的 Token 越多,花的钱就越多。不同的模型,处理相同数量 Tokens 的价格可能天差地别(通常越强越贵)。
- 响应速度: 处理的 Tokens 越多,模型思考和生成回复的时间就越长。
特别注意:警惕 LLM Agent 的 Token 陷阱!
如果你在用 LLM Agent(那种能调用工具、有自己思考流程的智能体),要格外留意 Token 的消耗。看下图这个 Agent,哪怕你只是问了个简单问题,它实际消耗的 Token 可能远超你的想象!
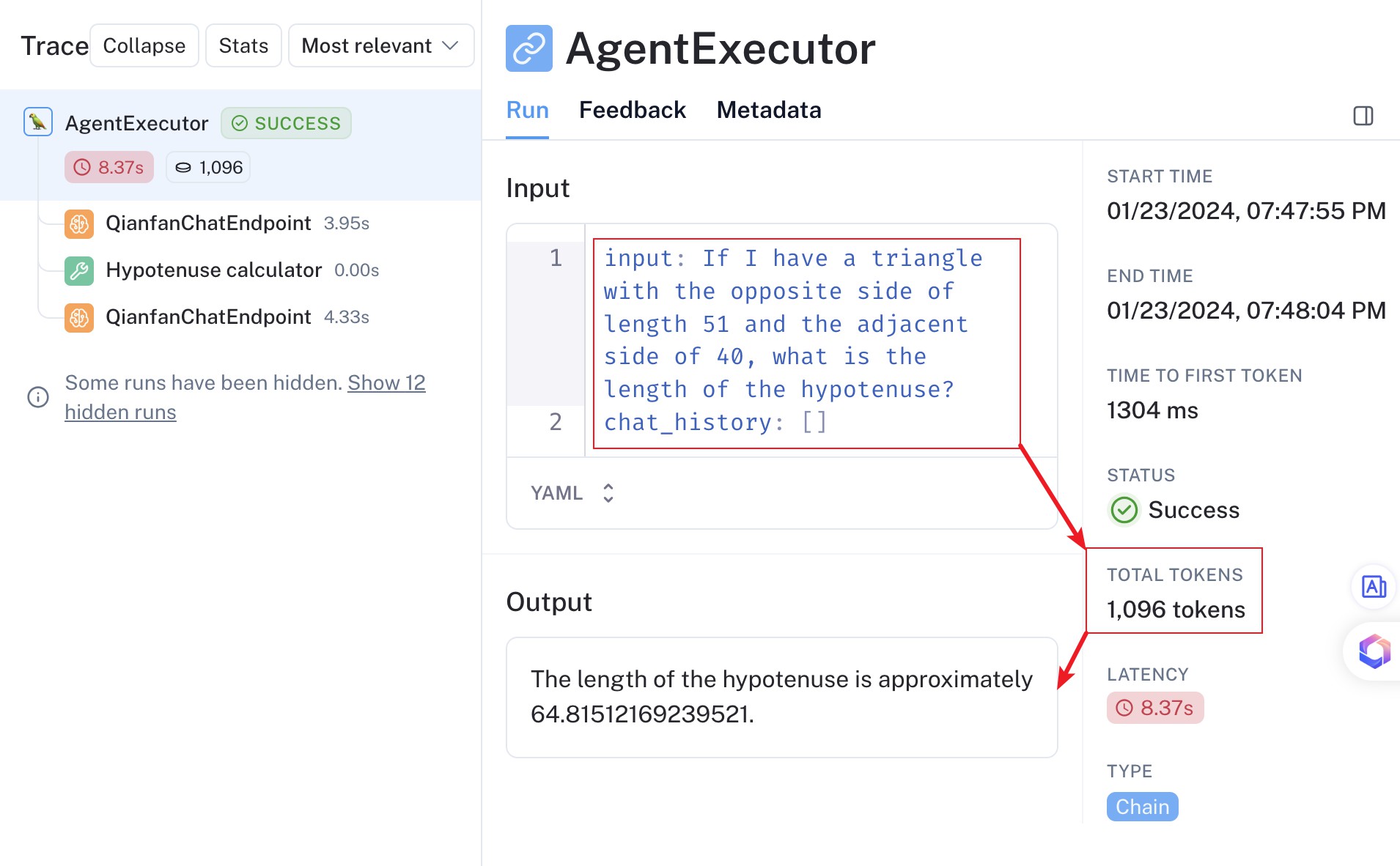
为什么 Agent 容易变成“Token 吞噬兽”?
- 多轮交互: Agent 为了完成任务,可能需要和 LLM 来来回回对话好几次(思考、调用工具、总结……)。
- 复杂的“说明书” (Prompt Template): 为了指导 Agent 如何行动,开发者通常会给它一个很长很复杂的指令模板(包含任务描述、工具列表、历史记录、思考步骤等),这些内容在每次与 LLM 交互时可能都需要重复发送,大大增加了 Token 数量。