Embedding
在机器学习和自然语言处理中,embedding 是指将高维度的数据(例如文字、图片、音频)映射到低维度空间的过程。embedding 向量通常是一个由实数构成的向量,它将输入的数据表示成一个连续的数值空间中的点。简单来说,embedding 就是一个N维的实值向量,它几乎可以用来表示任何事情,如文本、音乐、视频等。
对数据进行 embedding 的目的在于保留数据的内容或者其含义的各个特征。和不相关的数据相比,相似数据的 embedding 的大小和方向更接近,因此可以用于表述文本的相关性。
Embedding 的应用场景:
- 搜索:根据与查询字符串的相关性对结果进行排序
- 聚类:对数据按相似性分组
- 推荐:推荐具有相关内容的数据项
- 分类:对数据按其最相似的标签进行分类
- 异常检测:识别出相关性很小的异常值
Embedding 是一个浮点数类型的向量或列表。可以用向量之间的距离来测量它们的相关性:距离越小,表示相关性越高;距离越大,相关性越低。
获取 Embedding
可以根据 Embedding-V1 API 文档 的介绍,来获取基于百度文心大模型的字符串 Embedding。
还可以使用 @lst-langchain_embed_query_wx 的方式来获取相同的基于文心大模型的 Embedding。
python
embeddings = QianfanEmbeddingsEndpoint()
query_result = embeddings.embed_query("你是谁?")bash
[0.02949424833059311, -0.054236963391304016, -0.01735987327992916,
0.06794580817222595, -0.00020318820315878838, 0.04264984279870987,
-0.0661700889468193, ……
……]可视化
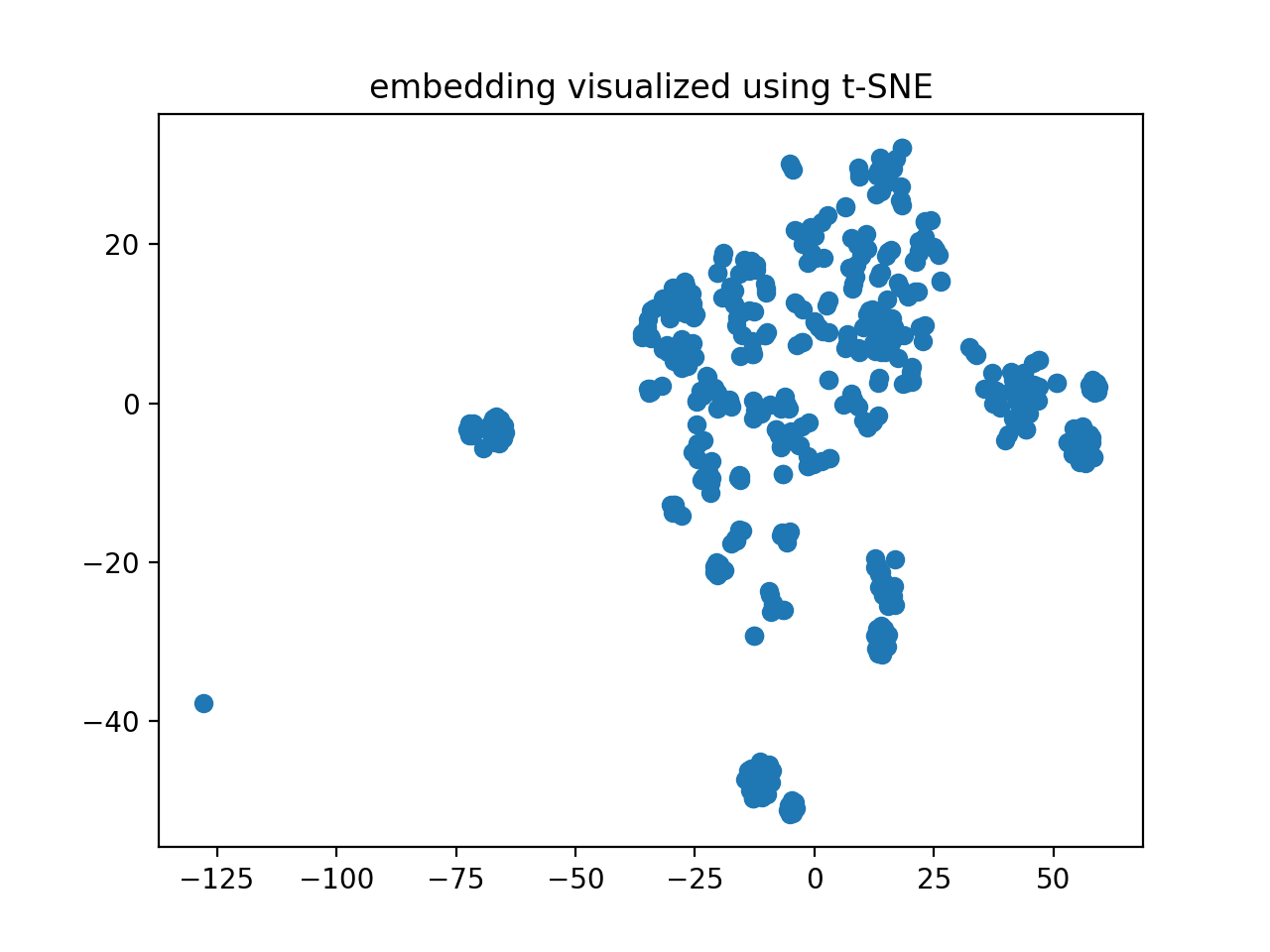
Embedding 一般是一种高维数据,为了将这种高维数据可视化,我们可以使用 t-SNE [-@tsne_online] 算法将数据进行降维,然后再做可视化处理。
利用 @lst-langchain_milvus_embedding 对文档进行向量化,然后将向量数据存储于 Milvus 向量数据库中(默认采用的 Collection 为 LangChainCollection)。
可以通过 Milvus 提供的 HTTP API 来查看指定的 Collection 的结构:
bash
http://{{MILVUS_URI}}/v1/vector/collections/describe?collectionName=LangChainCollection
- 初始化 Milvus 链接
- 选择 LangChainCollection
- 从 LangChainCollection 中检索特定数据
- 只提取结果中的 vector 字段,并生成新的列表
- 将 python 列表转换成矩阵
- 对向量数据进行降维
- 对低维数据进行可视化
结果如 @fig-vfe 所示: