2022 年 11 月,OpenAI 发布了 ChatGPT,这个聊天机器人一下子火遍全球。它不仅能和你流畅对话,还能写代码、写诗、写论文……ChatGPT 的出现,让大家真正感受到了大语言模型(LLM)时代的到来,甚至让曾经火热的“元宇宙”都显得有些黯然失色。

各大科技巨头,如谷歌、亚马逊、百度、阿里等,都纷纷投入巨资研发自己的大语言模型。
- 2023 年 2 月 8 日,谷歌发布了聊天机器人 Bard,但发布会上的演示出现了错误,导致谷歌股价大跌。
- 2023 年 2 月 24 日,Meta(Facebook 的母公司)开源了 LLaMA 模型,供研究使用。
- 2023 年 3 月 14 日,斯坦福大学基于 LLaMA 微调出了 Alpaca 模型,性能直逼 GPT-3.5。
- 同一天,OpenAI 发布了更强大的 GPT-4。
- 2023 年 3 月 16 日,百度发布了“文心一言”。
- 2023 年 4 月 11 日,阿里推出了“通义千问”。
- 2023 年 7 月 18 日,Meta 发布了 LLaMA 2。
- 2023 年 10 月 17 日,百度发布了“文心 4.0”。
- ……
学术界也掀起了大模型研究的热潮,相关论文数量呈爆炸式增长。


大语言模型家族
要了解大语言模型,就不得不提 Transformer。2017 年,谷歌提出了 Transformer 模型,它就像一个强大的“翻译机”,由多个“编码器”(Encoder)和“解码器”(Decoder)组成。Transformer 为大语言模型的发展奠定了基础。
后来,大模型的发展分成了两大流派:
- Encoder 流派(自编码模型): 就像一个“完形填空”高手,把句子中的一些词遮住,然后去猜这些词是什么。代表人物是 BERT。
- Decoder 流派(自回归模型): 就像一个“故事接龙”高手,根据前面的内容,预测接下来会说什么。代表人物是 GPT 家族。
一开始,BERT 这类“完形填空”模型发展迅猛。但是,OpenAI 的研究人员发现,只要不断扩大模型的规模(参数量、数据量、计算量),GPT 这类“故事接龙”模型的性能就会越来越好,这就是所谓的 Scaling Laws(规模法则)。于是,GPT 家族逐渐成为了大模型发展的主流。
GPT 的进化之路
OpenAI 在大模型领域的研究可谓是步步为营,他们通过不断探索和实践,让大模型的能力一步步显现出来:
- GPT-1 (2018): 提出了“预训练+微调”的方法。就像先让模型读大量的书(预训练),再针对特定任务进行专门辅导(微调)。
- GPT-2 (2019): 模型更大,数据更多,能力更强。不仅能完成特定任务,还能举一反三,处理一些之前没见过的任务(零样本/少样本学习)。
- GPT-3 (2020): 1750 亿参数的巨无霸!不仅能力更强,还学会了“上下文学习”(In-Context Learning,简称 ICL)。只要给它一些例子,它就能明白你的意图,完成任务。这使得“提示词工程”(Prompt Engineering)成为可能。GPT-3 还展现出了“涌现能力”(Emergent Ability),也就是在模型规模变大后,突然出现了一些意想不到的能力。
- Codex (2021): 基于 GPT-3,专门学习了大量代码,成为了编程高手。GitHub Copilot 就是基于 Codex 开发的。
- InstructGPT (2022,GPT-3.5): 更加听话,更能理解人类的指令。这是通过“基于人类反馈的强化学习”(RLHF)技术实现的。ChatGPT 最初就是基于 GPT-3.5。
从 2018 年到 2022 年,OpenAI 用了五年多的时间,一步步探索出了大模型的各种能力。
如何用好大语言模型?
面对如此强大的大模型,我们该如何使用呢?是自己从头训练一个,还是微调现有模型,还是直接用提示词工程?

下面这张图可以帮助你做出决策:

简单来说:
- 传统自然语言理解任务(如文本分类、情感分析): 如果你有标注好的数据,微调现有模型通常效果更好。
- 自然语言生成任务(如机器翻译、写作、画图): 大模型的强项!用提示词工程往往就能搞定。
- 知识密集型任务(需要大量背景知识): 可以用“检索增强生成”(RAG)技术,让大模型从外部知识库中获取信息。
- 推理任务: 大模型在规模变大后,推理能力会显著提升。但对于数学计算等任务,最好还是让大模型调用外部工具(Agent),避免“幻觉”(一本正经地胡说八道)。
大语言模型的不足
虽然大模型很强大,但它们并非完美无缺。除了性能、效率、成本等问题外,还有以下挑战:
- 安全问题: 大模型可能会生成有害、有偏见的内容,需要严格把控。
- 幻觉问题: 大模型有时会一本正经地胡说八道,需要特别注意。
- 实践验证: 需要更多真实场景的测试,确保模型能应对现实世界的复杂问题。
- 模型对齐: 要确保模型的行为符合人类的价值观。
- 模型可解释性: 我们对大模型内部运作机制的了解还很有限。

总的来说,大语言模型是人工智能领域的一项重大突破,但我们仍需不断探索和完善,让它们更好地为人类服务。
关键概念说明
Transformer 架构:Transformer 是 Google 于 2017 年提出的一种全新的神经网络架构,主要用于自然语言处理。它抛弃了 RNN 和 CNN,而是引入了注意力机制,实现 Encoder-Decoder 架构。Transformer 结构清晰,计算效率高,并可以进行并行计算,这使其在 NLP 任务上表现优异。
编码器模型:Encoder 用于理解输入的句子表达,输出向量表示输入句子的特征信息,例如
输入“I love NLP”,输出[0.1, 0.2, 0.3, 0.4]。解码器模型:Decoder 则基于 Encoder 的输出以及自身的上下文信息生成输出句子。例如
输入[0.1, 0.2, 0.3, 0.4],输出”I love machine learning“。编码器和解码器通过注意力机制交互。注意力机制:下面的例子演示了编码器和解码器通过注意力机制的交互过程,在这个过程中,编码器输出一次编码向量,代表输入句子信息。解码器每生成一个词,就会查询一次编码器的输出。并生成注意力分布,指出当前最重要的编码器输出内容。解码器结合注意力信息和自己的上下文,产生新的预测词。解码器每预测一个词,就将其加入到上下文,用于生成下个词。这个动态查询-生成的过程,就是编码器和解码器通过注意力机制进行交互。
输入句子:I love NLP。 编码器: 输入:I love NLP。 输出:向量[0.1, 0.2, 0.3, 0.4] 表示输入句子的特征信息。 解码器: 输入:[0.1, 0.2, 0.3, 0.4] 输出:I (此时解码器只生成了第一个词 I,将其作为上下文信息。) 注意力:解码器的注意力机制会查询编码器的输出[0.1, 0.2, 0.3, 0.4],并生成注意力分布[0.6, 0.2, 0.1, 0.1],表示解码器当前更关注编码器第1个输出元素。 解码器: 输入:[0.1, 0.2, 0.3, 0.4],[0.6, 0.2, 0.1, 0.1] 上下文:I 输出:love (解码器利用注意力分布所强调的编码器输出信息,以及自己的上下文I,生成love为当前最佳输出。) ..... 解码器最终生成:I love machine learning。自回归模型:Transformer 的 Decoder 需要每步生成一个词元,并将当前生成的词元信息加入到上下文中,用于生成下一个词元,例如模型
输入“I love”,输出“I love NLP”,然后基于“I love NLP”生成“I love natural language processing”,每一步都基于前面生成的内容生成新的输出,这一生成策略被称为自回归(Auto-regressive)。典型的 autoregressive 模型有 GPT-2、GPT-3 等。掩码模型:掩码语言模型(MLM)需要对输入文本中的一些词元进行掩码,然后训练模型基于上下文来预测被掩码的词元,例如
输入句子“I love [MASK] learning”,输出“I love machine learning”,模型需要填充[MASK]来预测掩码词,实现对上下文的理解。BERT 就是一种典型的掩码语言模型。
👏发展
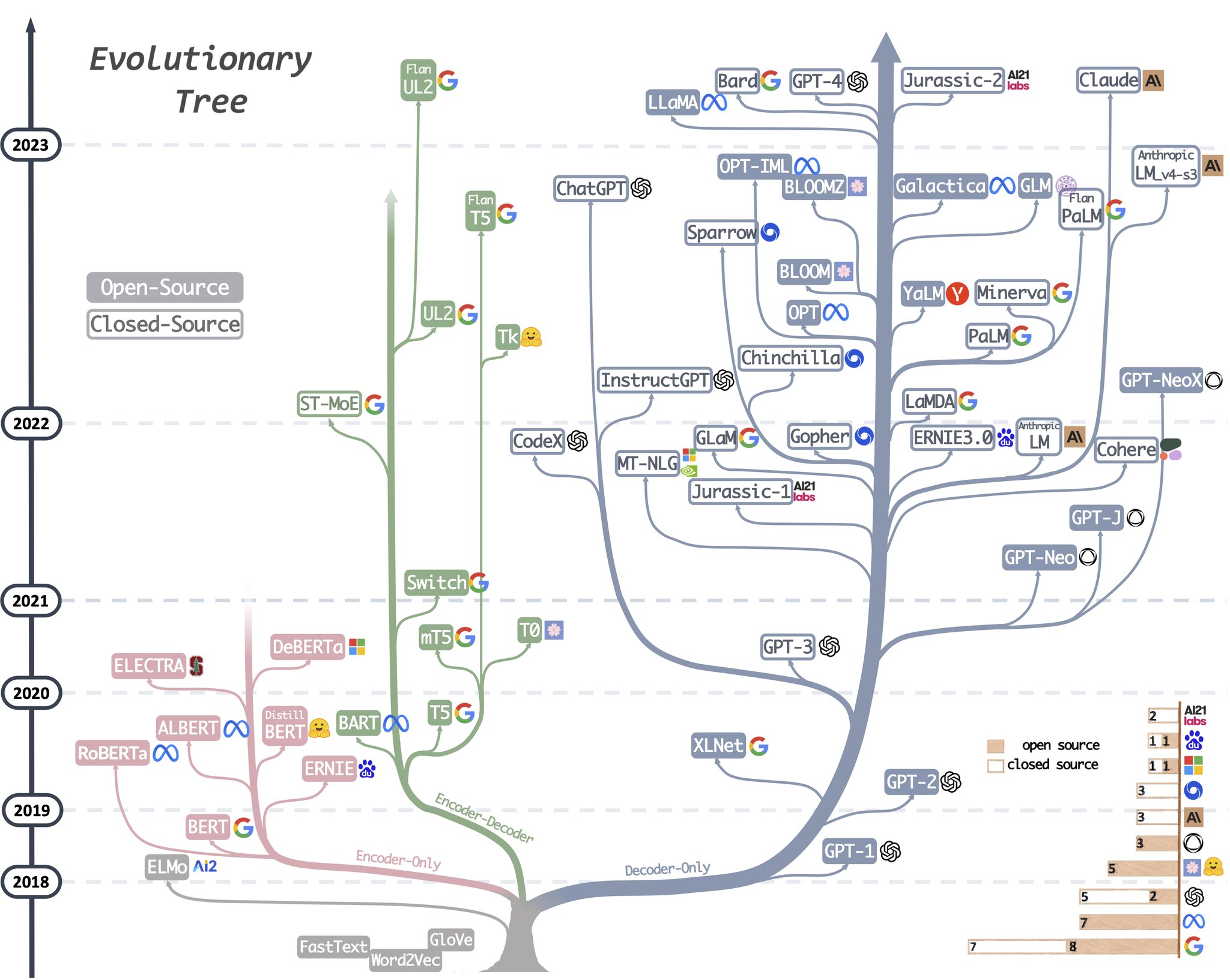
大语言模型进化树追溯了 LLM 的发展历程,重点统计了相对知名的模型,同一分支上的模型关系更近。不基于 Transformer 的模型用灰色表示,decoder-only模型是蓝色分支,encoder-only模型是粉色分支,encoder-decoder模型是绿色分支。模型在时间轴的竖直位置表示其发布时间。实心方块表示开源模型,空心方块则是闭源模型。右下角的堆积条形图是指各家公司和机构的模型数量。
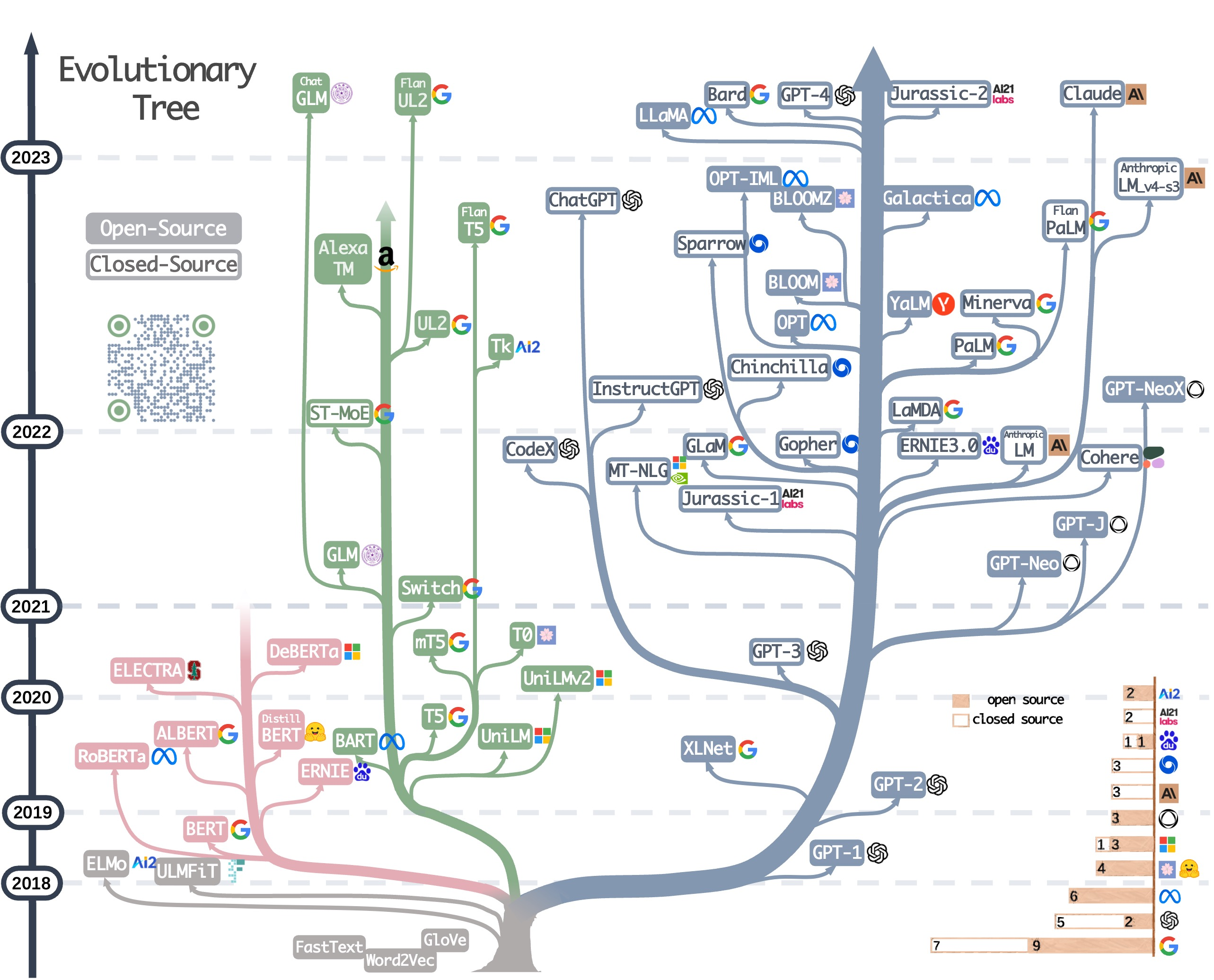
encoder-only 模型
掩码语言模型是一种常用的训练方法,它基于上下文来预测句子中被遮掩的词,使得模型能够更深刻地理解词与其上下文之间的关系。这些模型使用 Transformer 架构等技术在大型文本语料上训练,并在许多 NLP 任务中取得了最佳表现,如情感分析和命名实体识别。著名的掩码语言模型有 BERT、RoBERTa 和 T5。由于其在多种任务上的成功表现,掩码语言模型已成为自然语言处理领域的一种重要工具,但这些方法需要基于具体下游任务的数据集进行微调。在 LLM 的早期发展阶段,BERT 为仅编码器模型带来了初始的爆发式增长。(BERT主要用于自然语言理解任务:双向预训练语言模型+fine-tuning(微调))
decoder-only 模型
扩增语言模型的规模就能显著提升其在少样本或零样本时的表现,最成功的模型是自回归语言模型,它的训练方式是根据给定序列中前面的词来生成下一个词。这些模型已被广泛用于文本生成和问答等下游任务。自回归语言模型包括 GPT-3、PaLM 和 BLOOM。变革性的 GPT-3 首次表明通过提示和上下文学习能在少 / 零样本时给出合理结果,并由此展现了自回归语言模型的优越性。另外还有针对具体任务优化的模型,比如用于代码生成的 CodeX 以及用于金融领域的 BloombergGPT。在 2021 年GPT-3 的出现之后,仅解码器模型经历了爆发式的发展,仅编码器模型却渐渐淡出了视野。(GPT主要用于自然语言生成任务:自回归预训练语言模型+Prompting(指示/提示))
适用方向
- 自然语言理解:当实际数据不在训练数据的分布范围内或训练数据非常少时,可利用 LLM 那出色的泛化能力。
- 自然语言生成:使用 LLM 的能力为各种应用创造连贯的、上下文相关的和高质量的文本。
- 知识密集型任务:利用 LLM 中存储的广博知识来处理需要特定专业知识或一般性世界知识的任务。
- 推理能力:理解和利用 LLM 的推理能力来提升各种情形中制定决策和解决问题的能力。
参考链接
- 大语言模型发展历程:通过时间线的方式展示大模型的发布情况,从最初的GPT1到最新的PaLM2,非常清晰,而且是实时更新的
- 大型语言模型的实用指南:如果想了解在自己的业务中使用大语言模型,这里是一些最佳实践
- https://github.com/morsoli/llm-books/blob/main/LLMProjects/01-llm/01-1.md
- wangwei1237.github.io