深入浅出 Tokens:大语言模型(LLM)的基石
大语言模型(LLM)之所以能理解和生成文本,离不开一个关键概念:Tokens(分词)。你可以把 Tokens 想象成语言的“积木”,LLM 通过处理这些“积木”来理解和生成文本。
Tokens 可以是字母、单词、词组,甚至是代码片段,具体是什么取决于模型使用的 token 化算法(tokenization)。不同的算法会把文本切分成不同的“积木”。Tokenization 算法和 tokenizer 是 LLM 的基础组件。
在 token 化的过程中,每个 token 都会被赋予一个独一无二的数字编号(ID),模型真正处理的是这些数字编号。
认识 Tokens:OpenAI Tokenizer 工具
想直观地了解 Tokens?OpenAI 提供了一个在线的 Tokenizer 工具,你可以把一段文本输入进去,看看它是如何被切分成 Tokens 的。

INFO

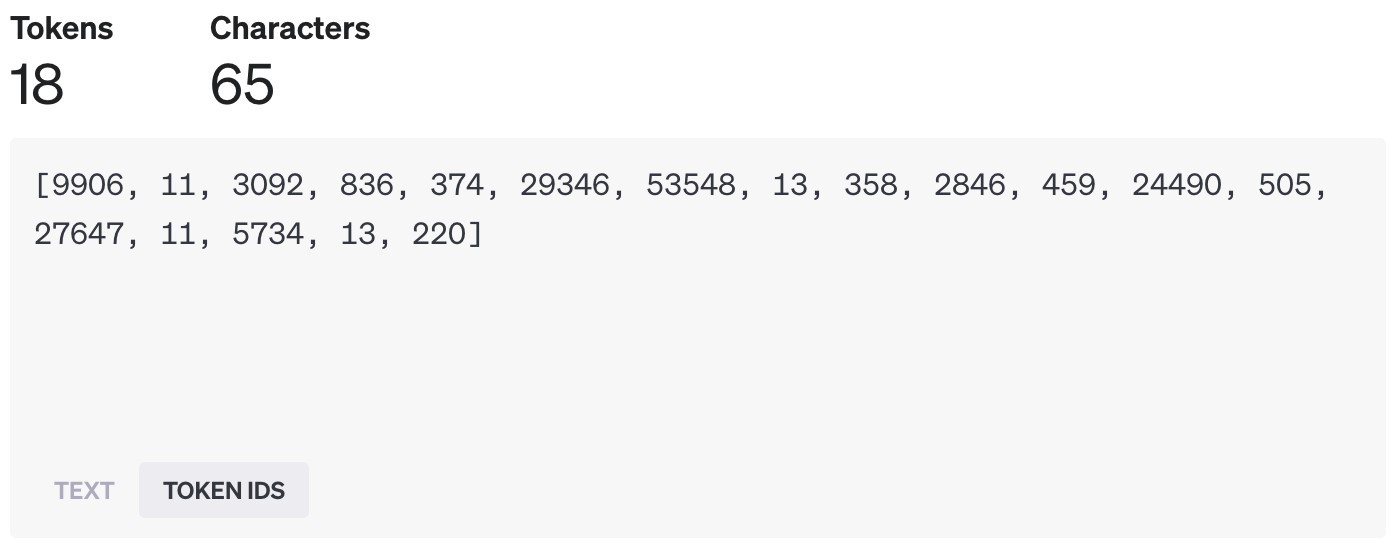
OpenAI GTP-4 tokenization 结果
在 OpenAI 的模型中,一个 token 大概相当于 4 个英文字母,或者说 3/4 个英文单词。
中文也可以进行 token 化,但有一些特殊之处。

INFO

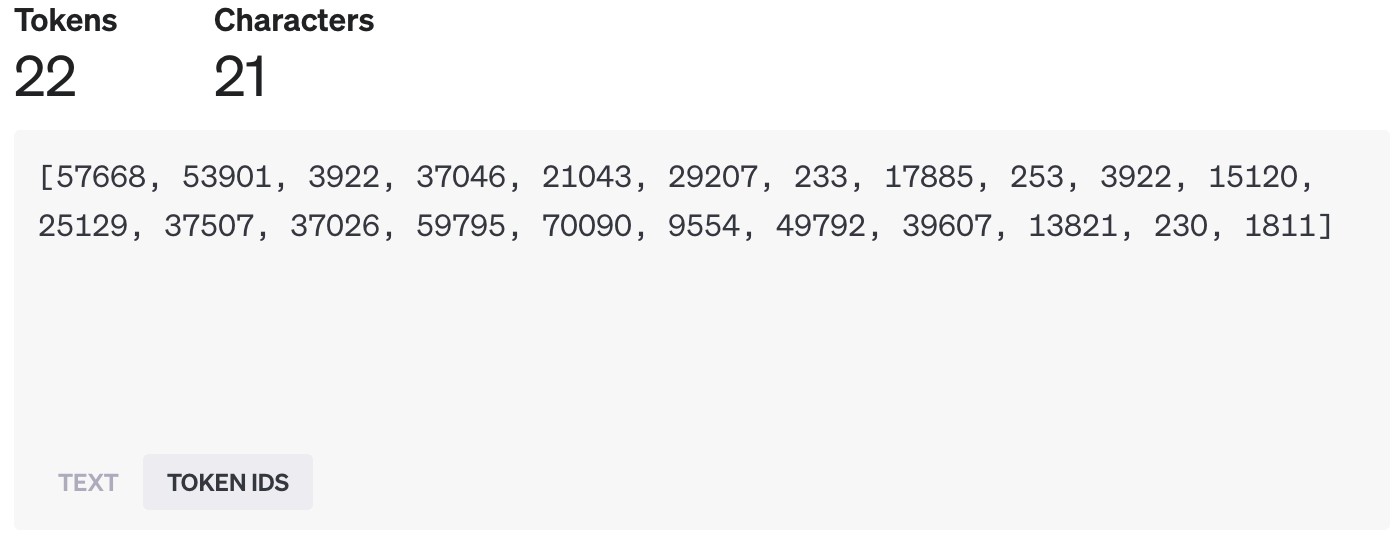
利用 OpenAI GTP-4 对中文进行 tokenization 的结果
DANGER
你可能会注意到 @fig-token_openai_c2 中有些乱码,这是因为有些中文字符比较特殊,一个字可能会对应多个 token。在线工具会把每个 token 里的字节单独显示出来,所以看起来像是乱码。
从 @fig-token_openai_c2 可以看出,中文的 token 化不一定是把每个汉字都变成一个 token,有时一个词会是一个 token。比如,“北京”就是一个 token,它的 ID 是 70090。
想在你的代码里使用 OpenAI 的 tokenizer?
- Python:可以用
tiktoken这个库。 - JavaScript:可以用
dqbd/tiktoken这个库。
百度也提供了类似的工具:千帆Token计算器。

常见的 Tokenization 算法
把文本切分成 Tokens 的过程,叫做 Token 化。Token 化算法有很多种,常见的有:
BPE (Byte Pair Encoding)
BPE 最早是一种数据压缩算法。想象一下,你有一串数据,里面有些字符组合经常一起出现,比如“aa”,“bb”。BPE 算法会把这些经常出现的组合替换成一个新的符号,比如“aa”变成“X”,“bb”变成“Y”。这样,原来的数据就变短了,达到了压缩的目的。
2015 年,有人把 BPE 算法引入到自然语言处理领域。2019 年,又有人提出了 BBPE (Byte-Level BPE) 算法,把 BPE 的思想从字符级别扩展到了字节级别。
OpenAI 用的就是 BPE 算法。BPE 可以帮助模型处理一些罕见的词,或者没见过的词,让文本的表示更紧凑。BPE 还允许模型通过组合已有的词或 token 来生成新的词或 token。词汇表越大,模型生成的文本就越多样、越有表现力。但是,词汇表越大,模型需要的内存和计算资源就越多。所以,词汇表的大小要根据模型的性能和效率来权衡。
WordPiece
WordPiece 与 BPE 类似,也是从一个小的词汇表开始,通过不断合并来产生最终的词汇表。
但 WordPiece 和 BPE 有一个重要的区别:BPE 是根据词频来选择合并哪些 token,而 WordPiece 是根据 互信息(可以理解为两个 token 之间的“相关性”)来合并的。
WordPiece 可以很好地平衡词汇表大小和 OOV 问题,但是可能会产生一些不合理的切分,而且对拼写错误很敏感,对前缀的处理也不够好。
Unigram Language Model (ULM)
ULM 的思路是:先准备一个很大的词汇表,然后计算如果去掉某个词或子词,对整个模型的“损失”有多大。损失越大,说明这个词或子词越重要,就把它留下来。
ULM 的优点是可以学习到一些“噪声”,但它的效果很大程度上取决于初始词汇表的好坏。
Tokens 与模型成本
Token 化会影响 LLM 需要处理的数据量和计算量。LLM 需要处理的 token 越多,消耗的内存和计算资源就越多。
所以,使用 LLM 的成本取决于:
- Token 化算法和模型使用的词汇表大小。
- 输入/输出文本的长度和复杂性。
不同的模型,处理相同数量的 tokens,费用可能差别很大。一般来说,越新的模型、能力越强的模型,费用越高。
- OpenAI 的 gpt-3.5-turbo-16k、gpt-4、gpt-4-32k 模型,以及百度的 ERNIE-Bot-turbo、ERNIE-Bot 4.0 模型,都有各自的定价。(具体价格请参考官方最新信息)
特别是对于 LLM Agent,我们更需要特别关注其 Token 的使用量。对于下图所示的 Agent,即便它只包含 2 个工具,即便我们向 Agent 提问的输入 Token 看起来不多,但是实际上却可能产生非常多的输入 Token。
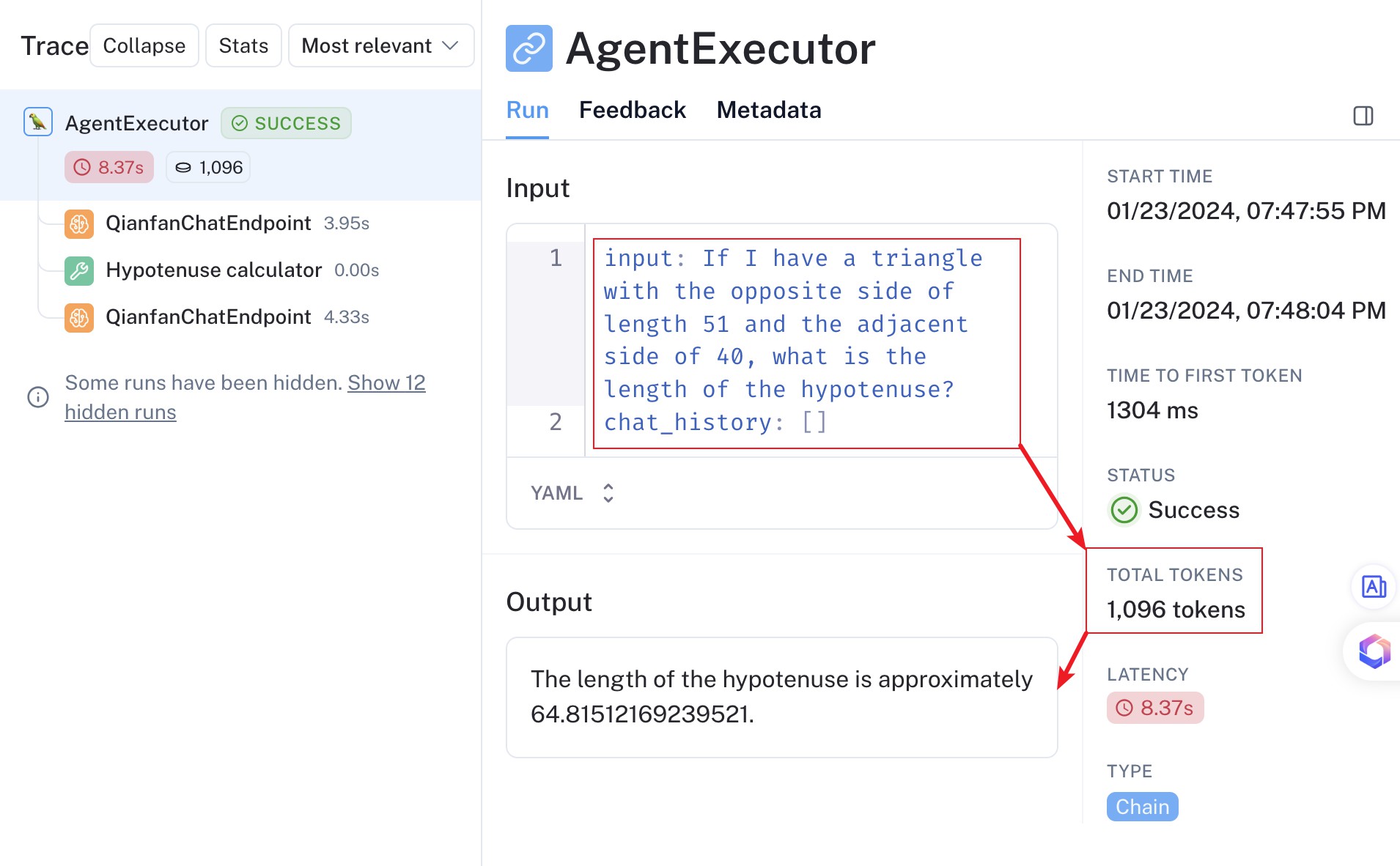
这是因为 Agent 需要与 LLM 进行多次交互,而且提示词模板通常比较复杂,这些都会导致 Token 数量的增加。
脚注解释:
- 互信息/凝固度/内聚度: 反映一个词内部两个部分结合的紧密程度。比如,“电影院”的“电”和“影”之间的凝固度就很高。
- OOV (Out-of-Vocabulary): 有些词不在模型的词汇表里,模型就没法处理这些词,这就是 OOV 问题。